 RU
RU EN
ENСпособы скрытия сайта от поисковых роботов: две надежные методики для предотвращения преждевременной индексации страниц.

Что такое индексация сайта
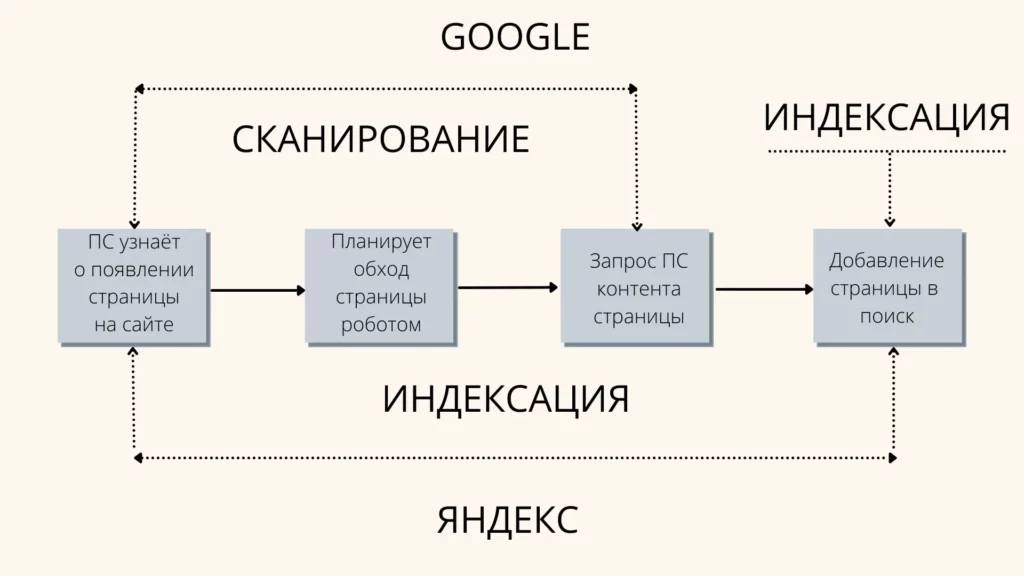
Индексация сайта — это процесс, в ходе которого поисковые роботы обрабатывают его страницы. Он необходим для того, чтобы информация о содержимом страницы была добавлена в базы данных поисковых систем.
Индексация состоит из трех этапов: сбор данных, их проверка на достоверность и сохранение полученной информации.
Качественные веб-сайты обычно быстро и автоматически индексируются. Однако иногда это может быть нежелательно, поскольку страницы могут быть добавлены в индекс до наступления нужного момента, что может негативно отразиться на ресурсе.
Потенциальные риски преждевременной индексации
Последствия преждевременной индексации могут быть разнообразными:
- Изменение структуры URL. При экспериментах с внешним видом ссылок существует риск того, что поисковый краулер проиндексирует временный вариант. Это может привести к длительному ожиданию, пока страница покинет индекс, и к появлению в результатах поиска ссылок на некорректные URL-адреса.
- Изменение дизайна сайта или другие глобальные изменения. Аналогично, в индекс могут попасть временные версии страниц, а не финальные.
- Неполнота оптимизации для SEO. Например, если не заполнены метатеги, не выделено семантическое ядро или ключевые фразы.
- Тестирование мобильной версии сайта. Поисковые системы могут индексировать несколько версий, что приведет к ошибкам в индексе.
Все эти случаи могут иметь серьезные последствия. Если вы захотите вернуться к предыдущей версии сайта, придется подождать, так как поисковые системы уже проиндексировали изменения, и в индекс попала некорректная версия сайта.
Как предотвратить индексацию страницы
При тестировании общих изменений можно запретить индексацию всего сайта. Если изменения касаются только одной страницы, достаточно запретить индексацию только этой страницы.

Как ограничить доступ к сайту для индексации с помощью robots
Метатег ‘robots’ позволяет контролировать отображение страницы в результатах поиска и влиять на ее индексацию.
Метатег можно вставить как в код страницы, так и в HTTP-заголовок.
Чтобы запретить отображение страницы в результатах поиска, добавьте следующий фрагмент в раздел ‘head’ страницы:
<meta name="robots" content="noindex" />Иногда необходимо запретить сканирование только определенным краулерам. Для этого нужно указать их user-agent. Например, чтобы запретить сканирование только поисковому роботу Google, добавьте следующую строку:
<meta name="googlebot" content="noindex" />Если добавление кода в HTTP-заголовок невозможно, этот же метатег можно добавить в код страницы:
<meta name="robots" content="noindex, nofollow">Таким образом, вы запрещаете индексацию страницы всем краулерам, которые понимают директивы стандарта исключения для роботов.
Вы также можете запретить индексацию:
- Всех изображений, опубликованных на странице:
<meta name="robots" content="noimageindex">- Страницы целиком только для поискового робота Google Новостей:
<meta name="Googlebot-News" content="noindex, nofollow">Теперь страница не будет отображаться в ленте Google Новостей.
Как ограничить индексацию сайта, папки или файла с помощью robots.txt
В файле robots.txt, стандарте исключения для роботов, можно ограничить индексацию как отдельных страниц, так и целых разделов сайта.
Хотя блокировка показа страницы путем редактирования файла robots.txt возможна, страница все равно может быть проиндексирована.
Все директивы в robots.txt рекомендательные, и краулеры могут их игнорировать.
Даже если указана запрещающая директива, страница или раздел могут быть проиндексированы. Кроме того, различные краулеры могут по-разному интерпретировать синтаксис директив, а некоторые поисковые системы вообще не поддерживают запрещающие директивы.
Google и «Яндекс» корректно обрабатывают robots.txt.
Чтобы предотвратить преждевременную индексацию всеми поисковыми системами, добавьте в файл robots.txt следующую строку:
User-agent: *
Disallow: /
Это формально сообщает поисковым роботам, что индексировать ваш сайт не нужно.
Чтобы запретить индексацию сайта только поисковому роботу «Яндекс», добавьте в файл robots.txt:
User-agent: Yandex
Disallow: /
Иногда необходимо защитить определенную папку от индексации. Для этого добавьте следующую строку в файл robots.txt:
User-agent: *
Disallow: /your_folder/
(замените ‘your_folder’ на имя закрываемой папки)
Также можно ограничить индексацию отдельного файла. Для этого добавьте следующую строку в файл robots.txt:
User-agent: Yandex
Disallow: /folder/your_file.php
(замените ‘your_file.php’ на имя закрываемого файла)
Если нужно предотвратить индексацию конкретного фрагмента текста, добавьте следующую директиву в код страницы:
текст, который не должен индексироваться
Тег распознается только краулерами «Яндекса».
Не путайте тег с директивой noindex, которую понимают краулеры Google. Чтобы предотвратить отображение страницы в результатах поиска Google, добавьте директиву noindex в HTTP-заголовок страницы или метатег в код страницы.
Заключение
Раннее обращение краулеров к страницам может нанести вред веб-сайту, если в индекс будут попадать дубликаты страниц или временные тестовые версии. Чтобы этого избежать, можно воспользоваться одним из трех методов:
- Указать инструкцию краулерам в HTTP-заголовке страницы.
- Задать соответствующую директиву в файле стандарта исключения для роботов (robots.txt).
- Внедрить специальный тег в код страницы для управления индексацией.
