 RU
RU EN
ENРекуррентные нейросети (RNN) играют важную роль в области машинного обучения, особенно при работе с последовательными данными. Они способны улавливать контекст и зависимости во времени, что делает их идеальным инструментом для анализа текста, речи, временных рядов и других последовательных данных. Рассказываем суть работы RNN и где они применяются.
Что такое рекуррентные нейросети
Рекуррентные нейросети (RNN) являются мощным классом искусственных нейронных сетей, способных обрабатывать и анализировать последовательные данные. В отличие от классических нейронных сетей, RNN обладают способностью запоминать информацию о предыдущих состояниях и использовать ее при обработке последующих входных данных.
Определение RNN отражает их основное свойство — возможность работы с данными, имеющими последовательную структуру, такую как тексты, речь, временные ряды и другие временные последовательности. За счет своей рекуррентной природы, RNN способны учитывать контекст предыдущих событий, что позволяет им эффективно моделировать и предсказывать зависимости в данных, основываясь на информации из прошлого.

Благодаря своим возможностям, RNN нашли применение во множестве задач, связанных с обработкой последовательных данных. Одной из основных областей применения является обработка естественного языка:
- Машинный перевод;
- генерацию текста;
- классификацию;
- анализ тональности текста.
RNN также широко применяются в задачах аудиообработки, обработке речи, предсказании временных рядов и других задачах, где важна работа с последовательными данными.
В работе с последовательными данными RNN демонстрируют способность моделировать зависимости внутри последовательностей и учитывать контекст предыдущего входа. Это достигается путем использования обратных связей, когда информация о предыдущем состоянии передается в следующие итерации обработки данных. Этот механизм позволяет RNN генерировать последовательности, анализировать их структуру и улавливать долгосрочные зависимости в данных.
Как работает рекуррентная нейросеть
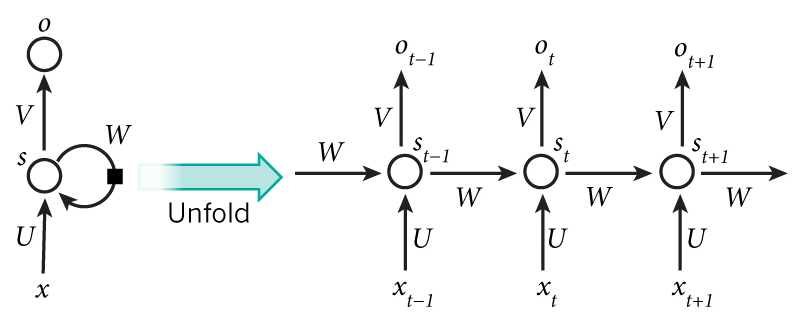
На представленной выше диаграмме явно отображается процесс развертывания рекуррентной нейронной сети в полную сеть. Развертывание представляет собой представление сети для всей последовательности данных. Например, если последовательность состоит из пяти слов, то развертка будет состоять из пяти слоев, где каждый слой соответствует одному слову. Формулы, определяющие вычисления в RNN, следующие:
- x_t: это входные данные на временном шаге t. Например, x_1 может быть вектором с одним активированным состоянием (one-hot vector), соответствующим второму слову в предложении.
- s_t: это скрытое состояние на временном шаге t. Это «память» сети. Значение s_t зависит от предыдущих состояний и текущего входа x_t и вычисляется следующим образом: s_t = f(Ux_t + Ws_{t-1}), где функция f обычно является нелинейной, например, tanh или ReLU. Значение s_{-1}, которое необходимо для вычисления первого скрытого состояния, обычно инициализируется нулевым вектором.
- o_t: это выходные данные на временном шаге t. Например, если нам требуется предсказать слово в предложении, то выходом может быть вектор вероятностей в нашем словаре. Вычисление o_t осуществляется с использованием функции softmax и зависит только от текущего скрытого состояния s_t: o_t = softmax(Vs_t).
Мы можем интерпретировать значение s_t как «память» сети. Значение s_t содержит информацию о том, что произошло на предыдущих временных шагах. Выход o_t вычисляется только на основе «памяти» s_t. Однако на практике все немного сложнее: значение s_t не может содержать информацию о слишком далеких временных шагах;
В отличие от традиционной глубокой нейронной сети, которая использует разные наборы параметров на каждом слое, RNN имеет одинаковые наборы параметров (U, V, W) на всех временных шагах. Это отражает факт того, что мы выполняем одну и ту же задачу на каждом временном шаге, используя только различные входные данные. Это значительно уменьшает общее количество параметров, которые необходимо обучать;
На представленной диаграмме выходные данные присутствуют на каждом временном шаге, но в зависимости от задачи они могут и не потребоваться. Например, при анализе эмоциональной окраски предложения целесообразно обратить внимание только на окончательный результат, а не на окраску после каждого слова. Аналогично, ввод данных на каждом временном шаге также может быть необязательным. Основным отличием RNN является скрытое состояние, которое содержит определенную информацию о последовательности данных.
Основные принципы RNN
В отличие от других типов нейронных сетей, таких как сверточные или полносвязные сети, RNN обладает способностью обрабатывать последовательную информацию и учитывать контекст, что делает ее особенно полезной для задач, связанных с текстом, временными рядами и естественным языком.
Общая структура RNN и ее отличия от других нейронных сетей
Основной принцип работы RNN заключается в использовании обратной связи, что позволяет нейронной сети сохранять информацию о предыдущей обработке данных. Это достигается путем передачи выхода предыдущего временного шага в текущий шаг. Таким образом, RNN обладает способностью запоминать и учитывать предыдущие состояния, что делает ее идеальным выбором для анализа последовательностей.
Архитектура одиночной рекуррентной ячейки
Одиночная рекуррентная ячейка (RNN cell) является основной строительной единицей RNN. Ее структура включает в себя6
- Входной слой, который принимает входные данные;
- скрытый слой, который содержит в себе информацию о предыдущем состоянии;
- выходной слой, который генерирует выходную информацию.
В каждом временном шаге RNN cell обновляет свое состояние на основе текущего входа и предыдущего состояния.
Принцип обратного распространения ошибки в рекуррентных нейросетях
Обратное распространение ошибки в RNN осуществляется в соответствии с принципами классического обратного распространения ошибки, но с добавлением временной компоненты. Во время обратного распространения ошибки, градиенты передаются с конца сети к началу, позволяя каждой ячейке обновлять свои веса с учетом ошибки, допущенной во всех предыдущих шагах. Таким образом, RNN обучается учитывать контекст и предсказывать последующую информацию более точно.
Проблема затухающего/взрывающегося градиента (LSTM, GRU)
Одной из основных проблем RNN является проблема затухающего/взрывающегося градиента, которая возникает при обратном распространении ошибки через большое количество временных шагов. В этом случае градиент может становиться очень маленьким или очень большим, что приводит к проблемам с обучением.
Для решения этой проблемы были предложены две основные архитектуры: LSTM (Long Short-Term Memory) и GRU (Gated Recurrent Unit). Обе эти архитектуры используют специальные механизмы, которые позволяют информации более эффективно передаваться через временные шаги, минимизируя затухание или взрыв градиента.
- LSTM использует специальную структуру ячейки с тремя воротами (input gate, forget gate и output gate), которые контролируют поток информации внутри ячейки.
- GRU, в свою очередь, использует два ворота (reset gate и update gate), чтобы регулировать поток информации. Оба подхода позволяют эффективно обучать RNN на долгосрочных зависимостях, минимизируя проблему затухающего/взрывающегося градиента.
Области применения RNN
- Языковая модель: может использоваться для генерации текста, имитируя стиль и содержание предоставленных образцов. Это означает, что RNN способна «восстанавливать» последовательности текста, сохраняя свою структуру и логику.
- Машинный перевод: также часто применяются в задачах перевода с одного языка на другой. Благодаря своей способности учитывать контекст и последовательность слов, рекуррентные нейросети обеспечивают более точные и естественные переводы, учитывая специфику языка.
- Распознавание речи: широко используются в системах распознавания и транскрибации речи. Они способны анализировать и интерпретировать акустические данные, переводя их в текст и позволяя пользователям взаимодействовать с устройствами голосового управления.
- Временные ряды: применяются для анализа временных данных, таких как финансовые временные ряды, погодные данные или данные о трафике. Благодаря возможности обработки последовательности данных, рекуррентные нейросети способны выявить закономерности и тренды во временных рядах, что делает их полезными в прогнозировании и предсказании будущих значений.
- Обработка естественного языка: Они могут использоваться для анализа и классификации текста, определения тональности высказываний, выделения ключевых слов и автоматического резюмирования текста. Благодаря способности учитывать контекст и последовательность слов, рекуррентные нейросети значительно улучшают точность и качество обработки текста.
