 RU
RU EN
ENПод конец года Instagram неожиданно выпустил довольно большую статью, описывающую главные принципы рекомендаций в алгоритмических лентах. Одной из таких лент является, например, сам Instagram. Мы подготовили перевод всей статьи и предлагаем вам ознакомиться.

Один из самых больших вопросов, с которым сталкивается рекомендательная система — оценка с опорой исключительно на прогностическую точность, а также, сосредоточенность на ряде других факторах, например, расширение пользовательских предпочтений. Для верной оценки важности этого вопроса, рассмотрим несколько смоделированных сценариев в динамике.
Пользовательские настройки при изменяемых условиях
Представьте, нам одинаково нравятся как боевики, так и комедии. Также, предположим, что оба жанра визуально выглядят как два шарика в корзине. Один красный, другой белый. Изначально они одинаково предпочтительны вам, как пользователю. Красный цвет обозначает боевики, а серый — комедии. Далее рассмотрим две простые модели динамического развития наших предпочтений.
Персонализация
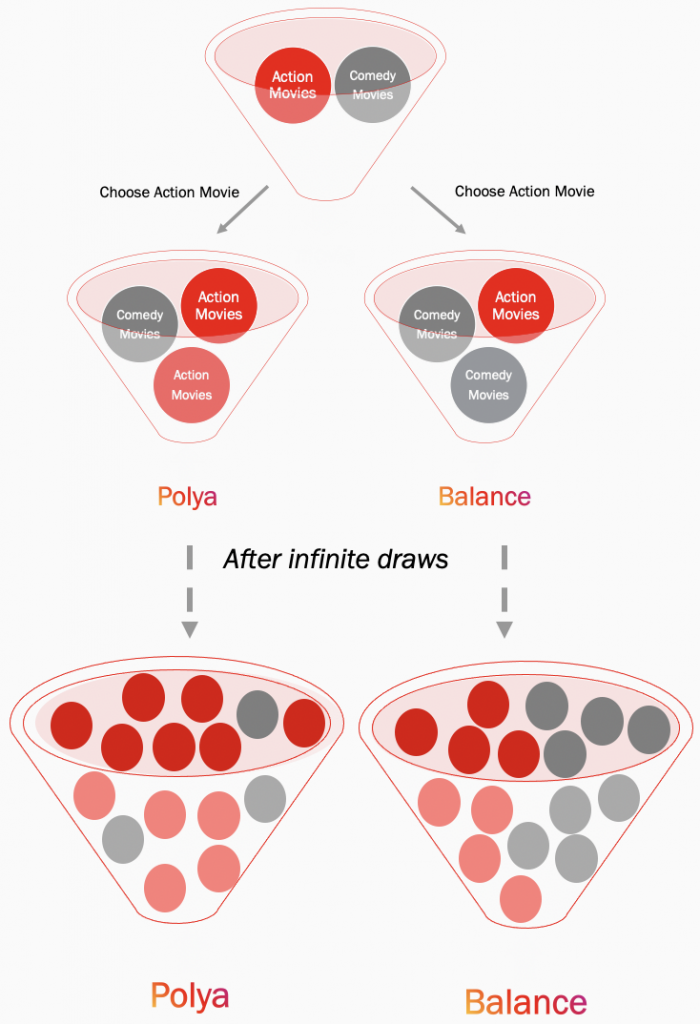
В этой модели мы случайным образом сперва достаем рандомный шарик, после добавляем в корзину этот шарик и такой же такого же цвета. Теперь в нашей корзине, если во второй раз мы выбрали боевик, два красных и один серый шарики. Это визуально показывает, что модель положительно усиливает наш выбор в пользу красного, а именно боевиков. То есть боевиков будет предложено посмотреть больше, потому что на данный момент, мы посмотрели их больше, а значит — нравятся они нам больше. В конце концов, после множества такого рода розыгрышей корзина будет полна. Количество шариков явно будет перевешивать в одну из сторон и изменить «нарисованную» картину, даже случайно, исправить невозможно. Этот процесс известен как Урна Пойя.
Урна Пойя — отличная модель для понимания самоподкрепляющихся динамических систем. Они имеют одинаково вероятные исходы, зависящие от пути. Говоря другим языком, если все одинаково вероятно, то после 100 розыгрышей вероятность того, что урна содержит 85 красных шариков, равна вероятности того, что она содержит 1 красный шарик. Но независимо от того, какой путь выбран, в равновесном состоянии (после бесконечных розыгрышей) один выбор сильно доминирует над другим. Если пользователю просто показать больше того, что он предпочитает в данный момент, он может застрять в небольшой вселенной, состоящей из множества вариантов его выбора.
Баланс
Во второй модели мы также случайным образом вытаскиваем один шарик из корзины и кладем его обратно, но второй шарик добавляем противоположного выбранному цвета. Итак, если мы выбрали красный шарик в первом случае, то наша корзина будет содержать один красный и два серых шарика. Эта модель, противоположно первой, отрицательно усиливает наш выбор. А значит в своей ленте нам будет показано меньше того, что нам нравится. После множества бесконечных розыгрышей корзина будет наполнена равным количеством шариков разного цвета. Процесс известен как процесс балансировки.
Баланс-процессы — отличная модель для самобалансирующихся динамических систем. Если мы будем агрессивно диверсифицировать, основываясь на текущие предпочтения пользователя, у нас получится предоставить ему больший набор возможных вариантов, но никогда не удастся привлечь его в краткосрочной перспективе.
Теоретически, мы могли бы иметь как систему, основанную на Урне Пойя, которая привлекает пользователя в краткосрочной перспективе, но приводит к скуке, потере вовлеченности и отсутствию предпочтений в долгосрочной перспективе. Так и систему, основанную на балансирующем процессе, которая не приводит к немедленному взаимодействию, но хороша для поддержания долгосрочного предпочтительного разнообразия.
Но какую систему выбрать? Мы опишем некоторые практические методы, которым следуют практики машинного обучения, чтобы выбрать пресловутую “золотую середину” между двумя крайностями для создания полезного опыта в долгосрочной перспективе с незначительными краткосрочными компромиссами.
Но прежде давайте обсудим некоторые основы.
Какими могут быть предпочтения в реальном мире?
В наших моделях, описанных выше, использование упрощенных предметов: статичных, точны и одномерных, значительно упрощает визуализацию процесса. На самом деле предпочтения имеют ряд следующих сложностей
Многомерность
Пользователь с равной вероятностью будет более глубоко вовлечен как в “черную комедию”, содержащую элементы триллера, так в общей комедию, из разряда — для всех.
Софт
Пользователь может демонстрировать различную степень предпочтений к типам контента, то есть 35% — к комедии и 99% — к спорту.
Контекстуальные: предпочтения наполнены смыслом с точки зрения предыдущего набора сделанных выборов, способа представления выбора, текущих тенденций и множества других факторов.
Динамика
Самый главный пункт. Предпочтения любого пользователя динамичны и меняются с течением времени. Например, человек, который любит исторические документальные фильмы в настоящее время, может не любить их уже через месяц.
С философской точки зрения проблема перемены или изменения рекомендаций звучит аналогично компромиссу между исследованием и эксплуатацией. Оптимальность выбора путей и вознаграждений может быть достаточно хорошо определена. Однако скрытые человеческие предпочтения и психика могут меняться после каждого сеанса.
Учитывая все эти сложности, довольно трудно придумать решение задачи оптимизации в замкнутой форме или же определить единственную целевую функцию. Далее мы обсудим некоторые практические методы, помогающие обеспечить более переменчивый пользовательский опыт при строгих количественных и качественных оценках.
Практические методы многообразия
Разнообразие уровня автора:
Что делать, если один и тот же автор продолжает появляться в ленте одного пользователя несколько раз? Простой отбор профилей с высоким рейтингом от разных авторов может улучшить общий пользовательский опыт.
Уровень типа носителя:
Для платформ с разным контентом и содержанием, поддерживающих множество форматов (фотографии, альбомы, короткие видео, длинные видео) и т. д., По возможности последовательность форматов лучше всего разнообразить.
Проще объяснить на примере: если алгоритм ранжирования выбирает три видео, а затем две фотографии для показа, то желательно смешать фотографии и видео между собой. Только если это не повредит общим количественным и качественным показателям.
разнообразие семантики:
Пользователь может получить рекомендуемые видео с контентом о баскетболе от нескольких авторов за один сеанс пролистывания ленты. Это самый сложный вид для поддержания разнообразия.
Лучший способ создания разнообразия на уровне контента — разработать высококачественный инструмент или набор инструментов, которые используются для создания и управления цифровым контентом.
В Instagram мы создали ряд самых современных систем анализа фотографий, видео и текста в масштабе. С их помощью обеспечивается как детальное, так и общее понимание медиа-элемента.
Пример: на фотографии могут быть птицы, закат и тигр. Также на фотографии может быть природа на более высоком семантическом уровне. Если бы мы могли классифицировать предпочтения пользователя как облако концепций (учитывая сходства), стало бы легче пробовать различные концепции и, следовательно, обеспечить более разнообразный опыт.
Изучение сходных семантик
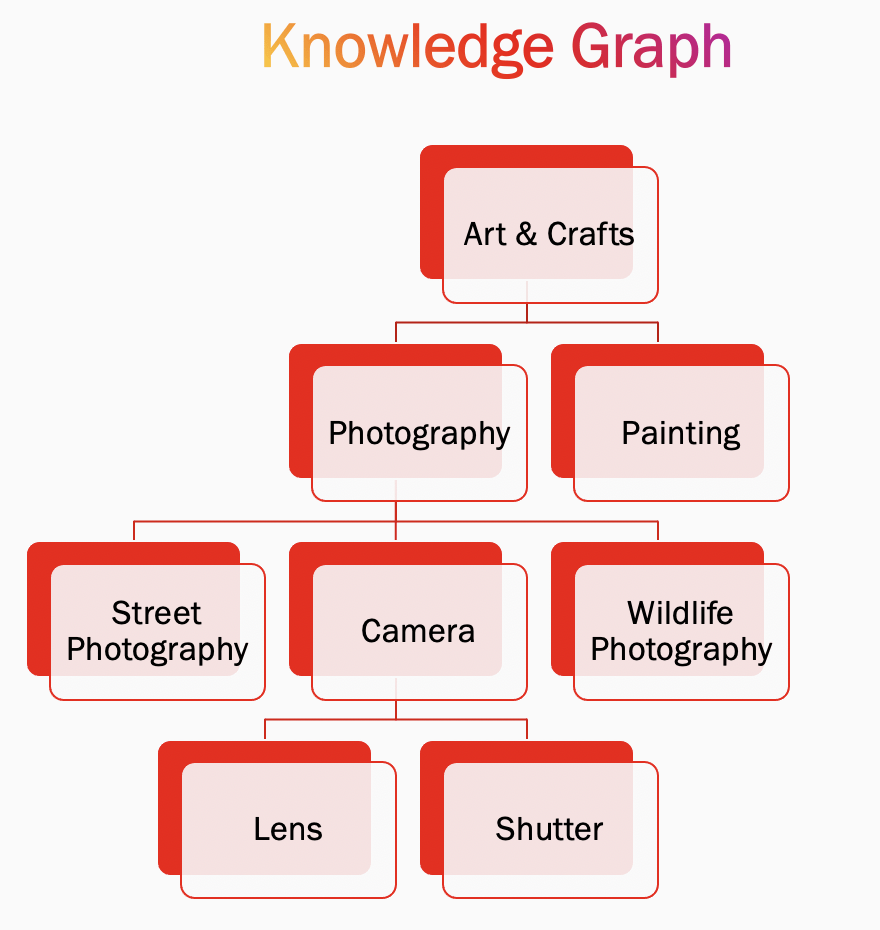
Большинство систем понимания контента представляют данные в виде граф или древа. Например, фотография дикой природы может быть концепцией более низкого уровня, ведущей к фотографии, которая, в свою очередь, ведет к искусству и ремеслам. Как только мы узнаем основные концепции, которые обычно интересуют пользователя, мы можем исследовать следующие направления:
- Исследование разных сторон концепций: Если пользователь интересуется фотографией дикой природы, то, скорее всего, он может быть заинтересован и в фотографии в целом. В живописи, как в своеобразном родоначальнике фотографии. А также в схожих концепциях, например, уличная фотография. Или, как вариант, в наименее отражающих тему концепциях, например, освоение нового объектива.
Изучение всех вариантов концепции на пользователях — на основе доказательства, что подобным пользователям они также нравятся, — определенно может привести к более разнообразному опыту. - Источник имеет значение: пользователь, вполне вероятно, никогда не сталкивался с тысячами нишевых концепций (например, манга, фестивали народных танцев, жесткая научная фантастика), а они могут быть довольно интересными для этих пользователей. Изучение их может привести к более разнообразному опыту.
- Мультимодальные элементы: элементы, которые захватывают сразу несколько режимов, а не один. Как правило, такие элементы являются хорошими данными для анализа. К примеру, если пользователь сильно интересуется машинным обучением и фотографией дикой природы, возможно, сообщение в блоге о применении методов ML для сохранения дикой природы могут быть для него особенно интересными.
- Поддержание долгосрочных и краткосрочных предпочтений: у каждого есть вещи, которые обычно интересуют долго, и, возможно, ряд вещей, которые сильно интересуют только в данный момент времени. Поддержание этих двух отдельных очередей приоритетов, обозначающих долгосрочные и краткосрочные интересы пользователя, может привести к лучшему разнообразию в долгосрочной перспективе.
- Использование алгоритмов компромисса «исследуй — используй «: методы компромисса «исследуй — используй» на основе подкрепляющего обучения могут обеспечить систематический механизм разнообразия предпочтений пользователей. Вот несколько примеров:
- Эпсилон-жадный алгоритм: в этом методе мы персонализируем без какого-либо семантического разнообразия, подвергая время от времени пользователя почти похожему элементу случайным образом.
- Верхняя порог доверия: допустим, мы знаем, что пользователь проявил умеренную вовлеченность к некоторым концепциям, но не был достаточно подвержен им. Соответственно, мы могли бы исследовать все концепции умеренного интереса на пользователе достаточное количество раз, до тех пор пока у нас не будет достаточно уверенности в необходимости их исключения.
- Компромисс: мы в Instagram ценим качественные показатели, такие как удовлетворенность пользователей и вовлечение, так же, как и количественные показатели, такие как ROC-AUC или NDCG. Проводим качественные исследования, опросы пользователей, дневниковые исследования и т. д. с целью выяснить общую терпимость к повторяемости и восприимчивость к разнообразию. Также, мы принимаем многие из наших возможных решений о развертывании модели, основываясь на том, насколько мы уверены в качестве определенного подхода к моделированию.
- Негативные ограничения: пользователи сами не всегда любят разнообразие и иногда (но не всегда) дают явную отрицательную обратную связь. Отрицательная обратная связь со стороны пользователя: нажатие кнопки “не заинтересован” или “показать меньше таких видео”. Мы учитываем эти негативные сигналы и используем их в качестве ограничения показа подобной рекламы для этого пользователя. Также, мы построили специальные модели ML, уменьшающие отрицательную обратную связь. Мы настраиваем эти модели на автономное моделирование и анализ результатов опросов удовлетворенности пользователей.
В завершении
Если вы руководствуетесь исключительно ориентированными на машинное обучение метриками, такими как NDCG, или ориентированными на продукт метриками, например, количеством лайков, это может привести к скуке и отключению. Мы же рекомендуем оптимизировать их для обеспечения долгосрочной удовлетворенности пользователей. Если вы хотите узнать больше об этом или заинтересованы в присоединении к одной из наших команд, пожалуйста, посетите нашу страницу и следите за нами на Facebook.
? Не забывайте подписаться на канал и вступить в чат:
Больше годноты на канале — Довольный Арбитражник
Обсудить и задать вопросы в чате — Арбитраж трафика | Довольный
