 RU
RU EN
ENДанный мануал пошаго описывает процесс создания своей ИИ модели для различных сайтов и соц.сетей. Генерация фото и видео с одним персонажей (в нашем случае девушкой) для ведения социальных сетей. Гайд подготовлен пользователем @Novoreg специально для дейтинг партнерки MTraf.io и приватного чата.

Далее текст от автора мануала
Предисловие перед запуском instagirl 2.5 (wan 2.2) с помощью ComfyUI в Runpod
Всем привет, в этом уроке мы запустим лору instagirl 2.5 для Wan 2.2 в ComfyUI в арендованном сервере с GPU в Runpod. Инструкция подходит для новичков и является по сути вводным уроком. Если этот урок получит положительный отклик, будет еще другие уроки, такие как обучение лоры для генерации изображения и видео с одним и тем же человеком. Постепенно мы придем к реализации телеграм бота для serverless генерации изображений и видео по требованию.
Если вы из России для реализации этой инструкции вам понадобится иностранный vpn и иностранная карта (или криптовалюта) для оплаты Runpod.

Регистрация и пополнение счета в Runpod.
Регистрируемся в Runpod.io (реф, при пополнении баланса на 10$ и более получаете рандомно от 5$ до 500$)| не реф и переходим в биллинг. Пополняем свой счет с помощью иностранной карты или криптовалюты (минималка 10$).
Создание Storage
Запуск мы будем делать с использованием Storage. Это память (диск) который мы арендуем для хранения наших моделей и прочих данных. Необходимо это для того чтобы каждый раз не загружать тяжеловесные gguf модели и safetensor. Переходим в Storage и нажимаем New network volume. Перед нами откроется окно:
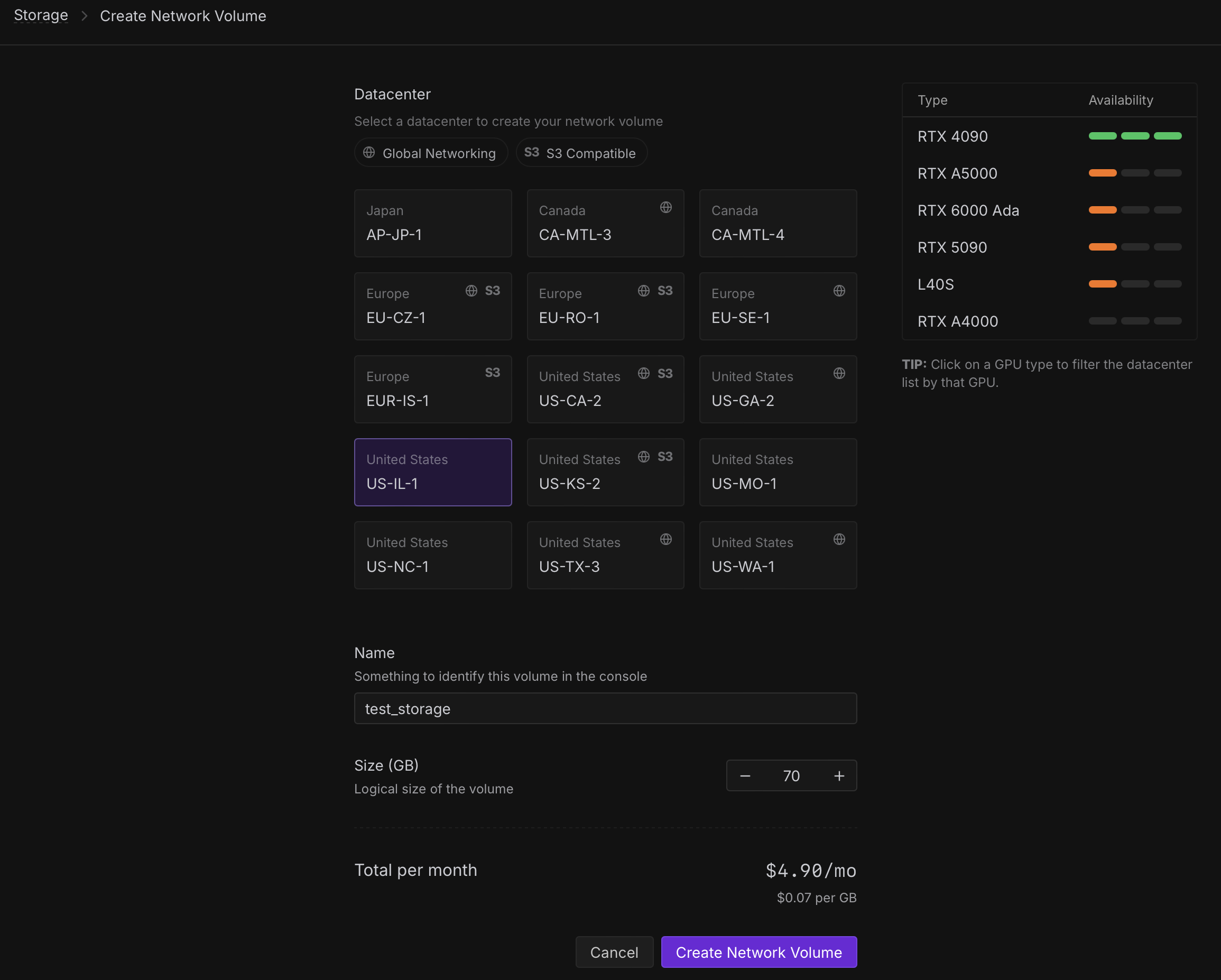
Здесь мы можем выбрать дата центры где будет наше хранилище. Справа можно увидеть доступные GPU в каждом дата центре, шкала отображает количество свободных GPU. Важно выбрать дата центр исходя из наших потребностей в GPU Мы будем запускать нашу модель на L40S. По этой причине выбираем дата центр US-IL-1, US-NC-1 или US-TX-3 (необходимо выбрать дата центр с большим количеством свободных GPU L40S). Обязательно написать имя нашего хранилища (любое удобное вам) и выбираем необходимый объем памяти (в нашем случае 70гб). Это будет стоить нам 4.90$ в месяц. Оплата почасовая. нажимаем Create network storage и наше хранилище будет создано.
Запускаем POD
POD — простыми словами это сервер с GPU на котором мы будем запускать наши модели. Переходим в Pods. Перед нами откроется окно:
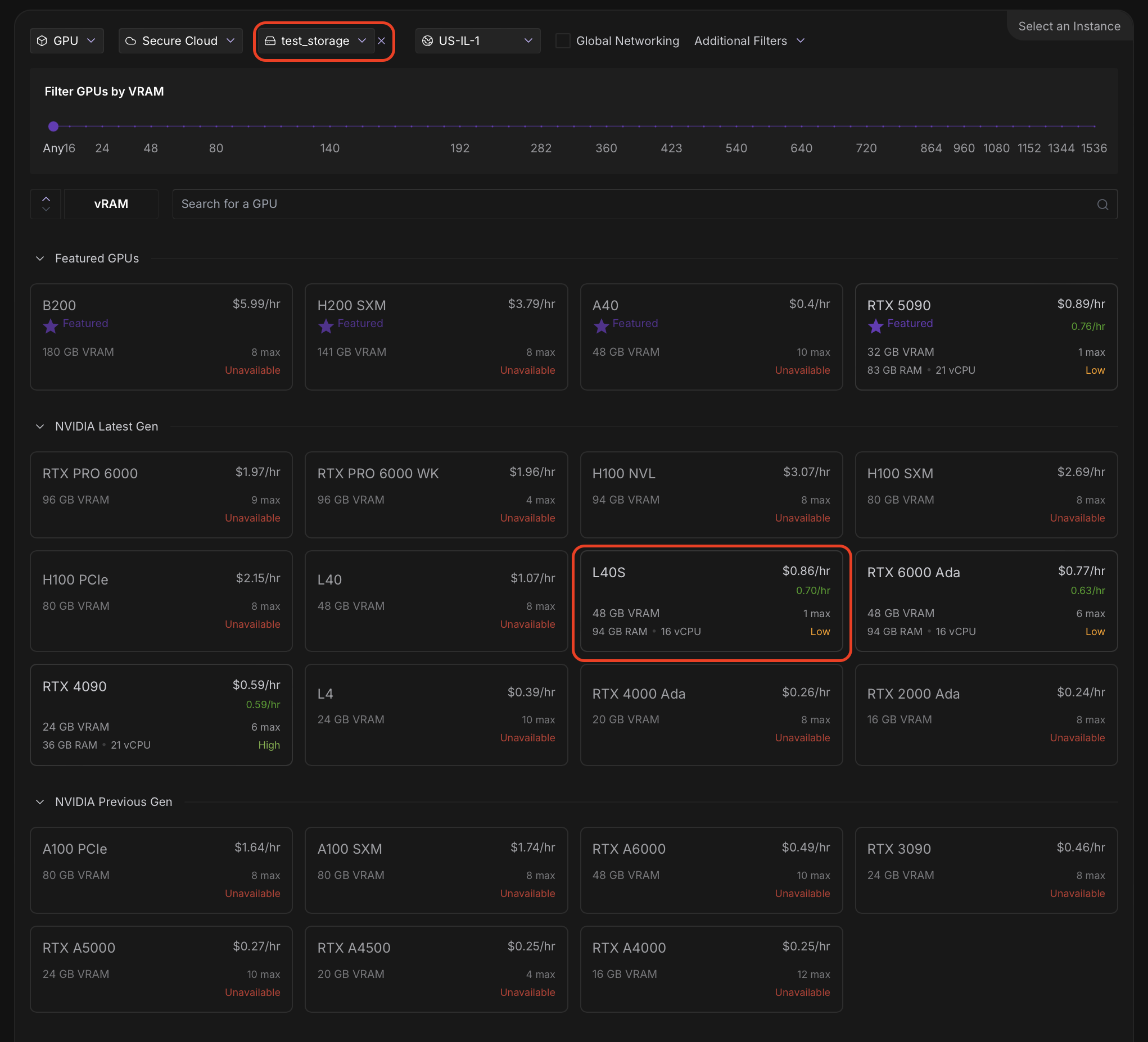
Сверху мы выбираем нами созданное хранилище, снизу нажимаем на желаемый GPU (у нас будет L40S). После выбора GPU мы увидим:
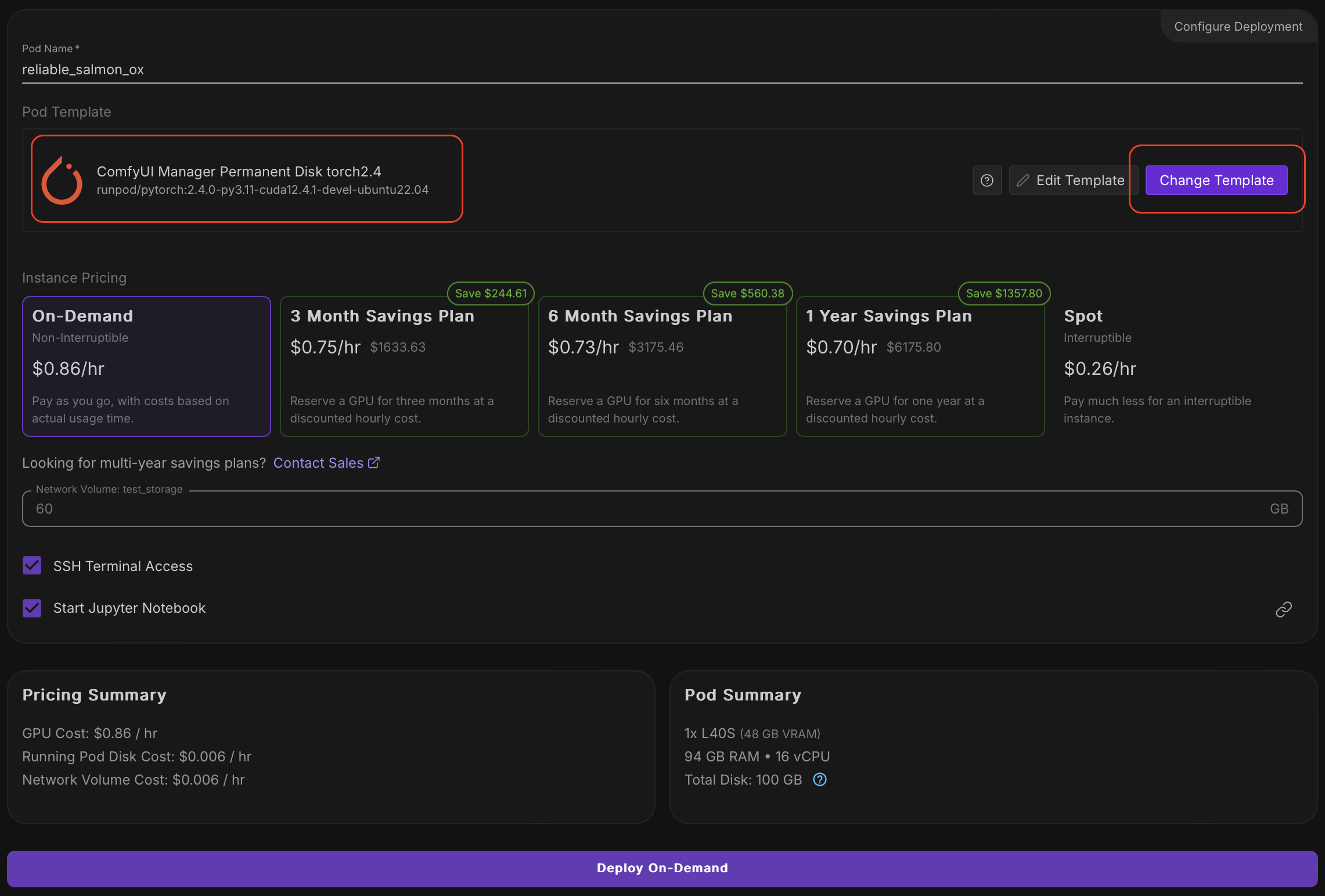
Тут нам необходимо нажать Change Template и выбрать ComfyUI Manager Permanent Disk torch2.4 (это уже подготовленный образ с ubuntu, cuda и предустановленными pytorch и comfyui). Все остальные настройки должны соответствовать скрину. Жмем Deploy On-Demand. После этого наш сервер начнет запускаться и нам надо дождаться статуса Ready у сервиса JupiterLab (при первом запуске на это может уйти до 5 минут)
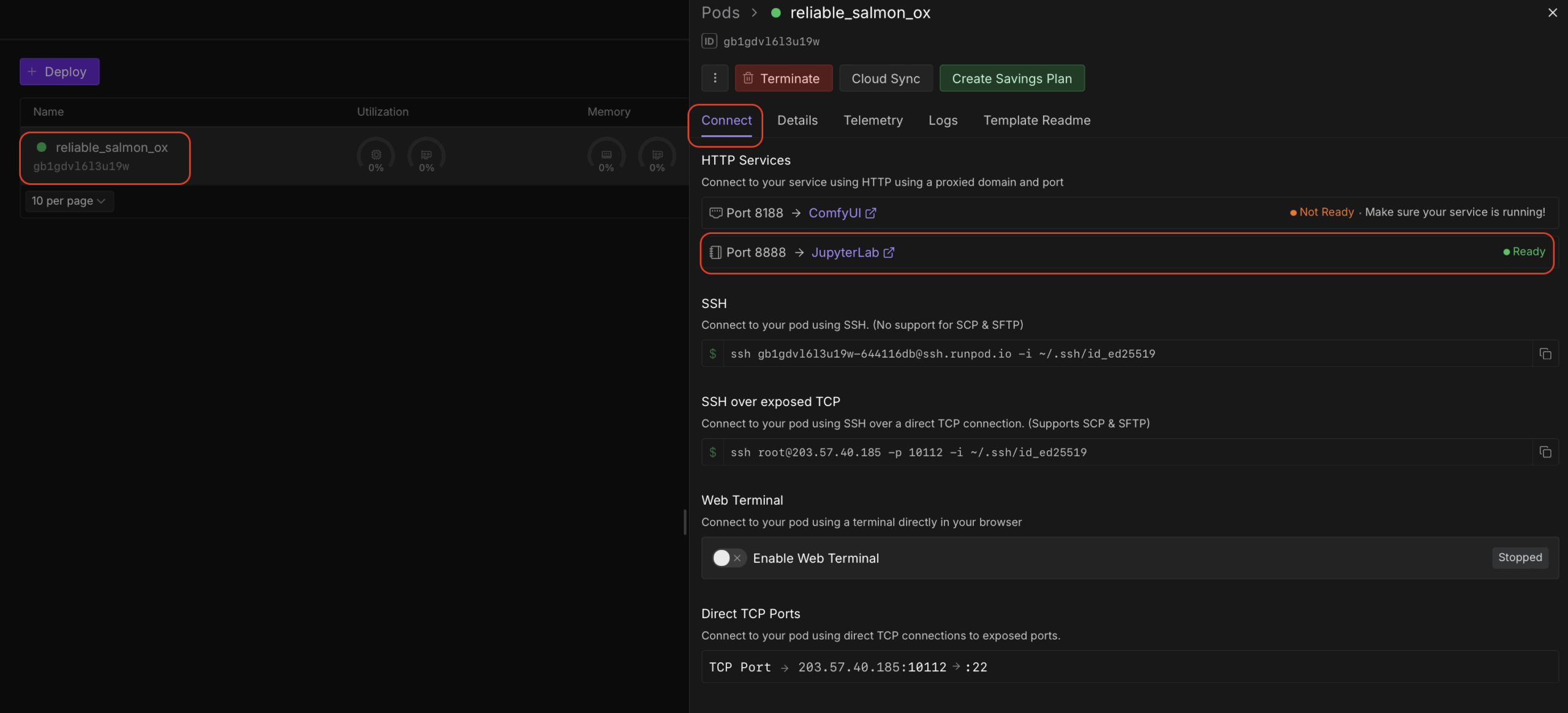
После этого в браузере откроется JupiterLab:
Тут /workspace это директория в нашем хранилище, которая будет всегда пока мы не удалим хранилище. Тут мы можем хранить наши данные не опасаясь того что они пропадут после отключения сервера. ComfyUI а нас находится в папке ComfyUI. Открываем его и находим папку models. Тут и будут храниться наши модели и прочие данные необходимые для работы. Теперь мы запустим терминал чтобы оттуда запустить наш ComfyUI:
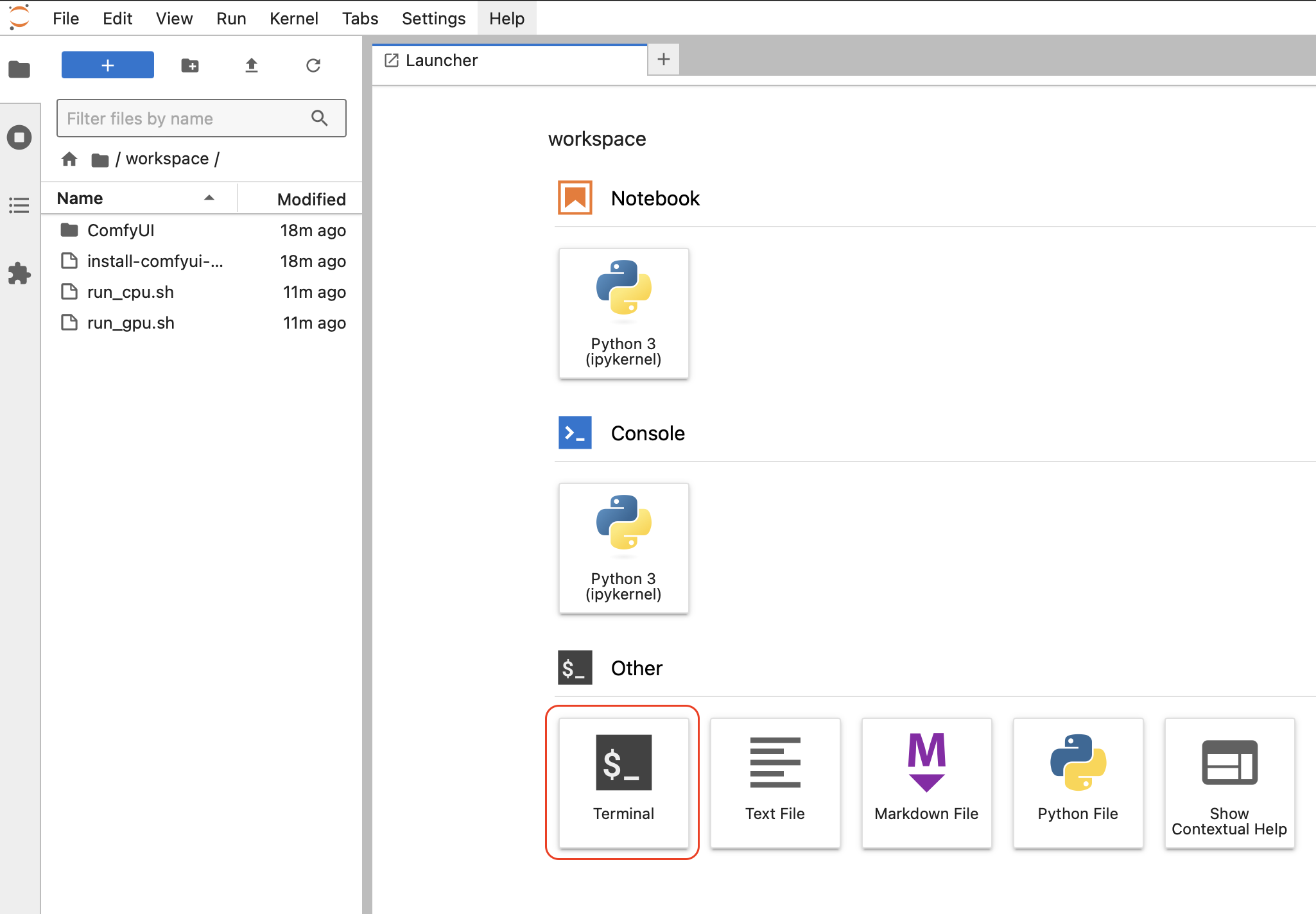
Но сначала установим sageattention (команда source /workspace/ComfyUI/venv/bin/activate и pip install sageattention), который ускоряет генерацию изображений:
Для запуска ComfyUI в терминале набираем команду ./run_gpu.sh и жмем Enter
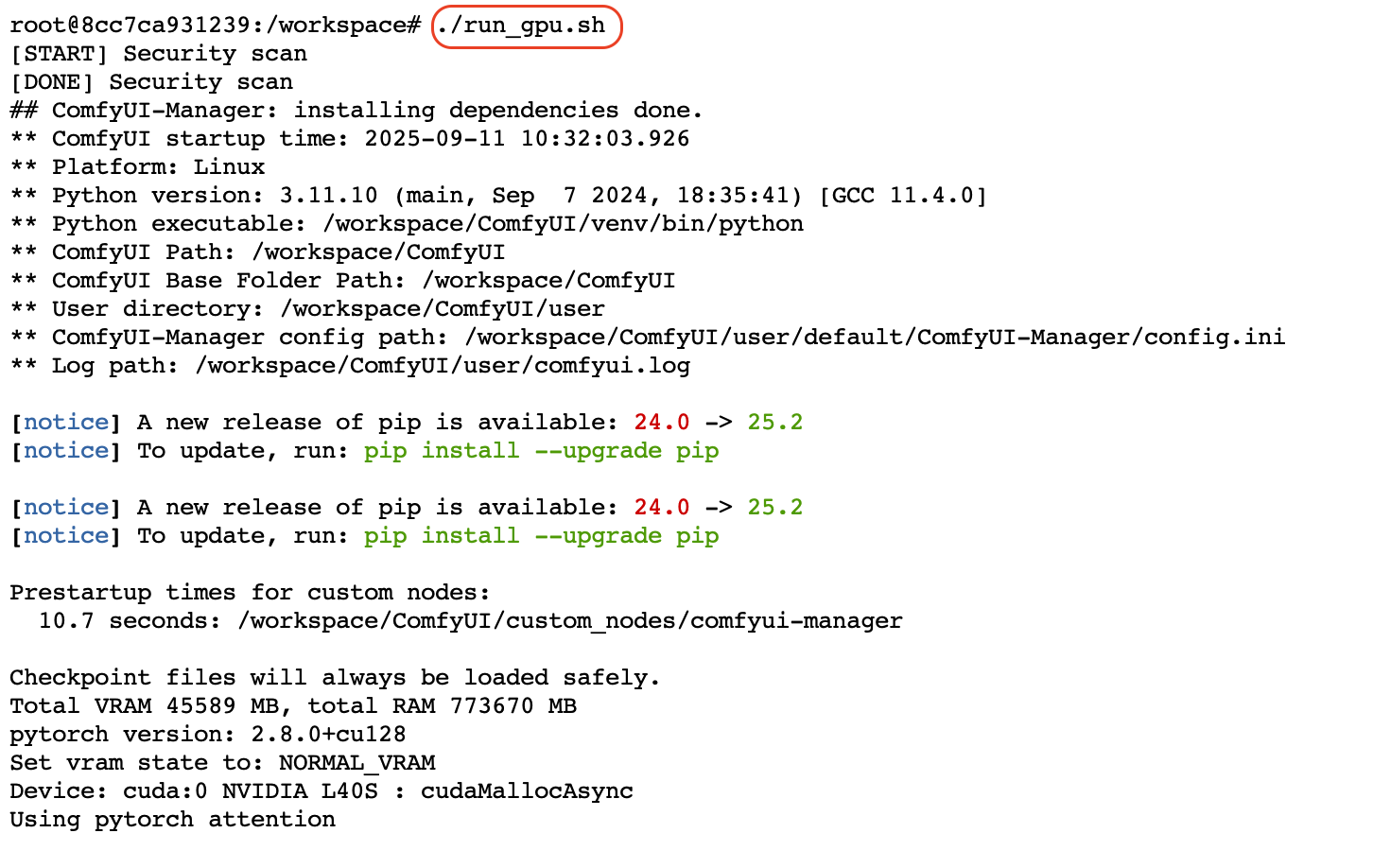
Ждем окончания процесса запуска и вывода сообщения:
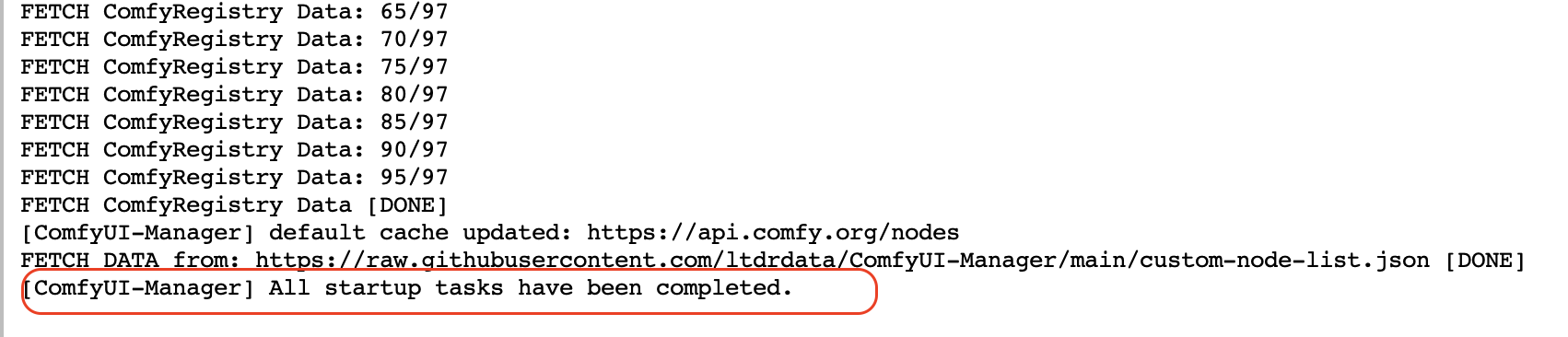
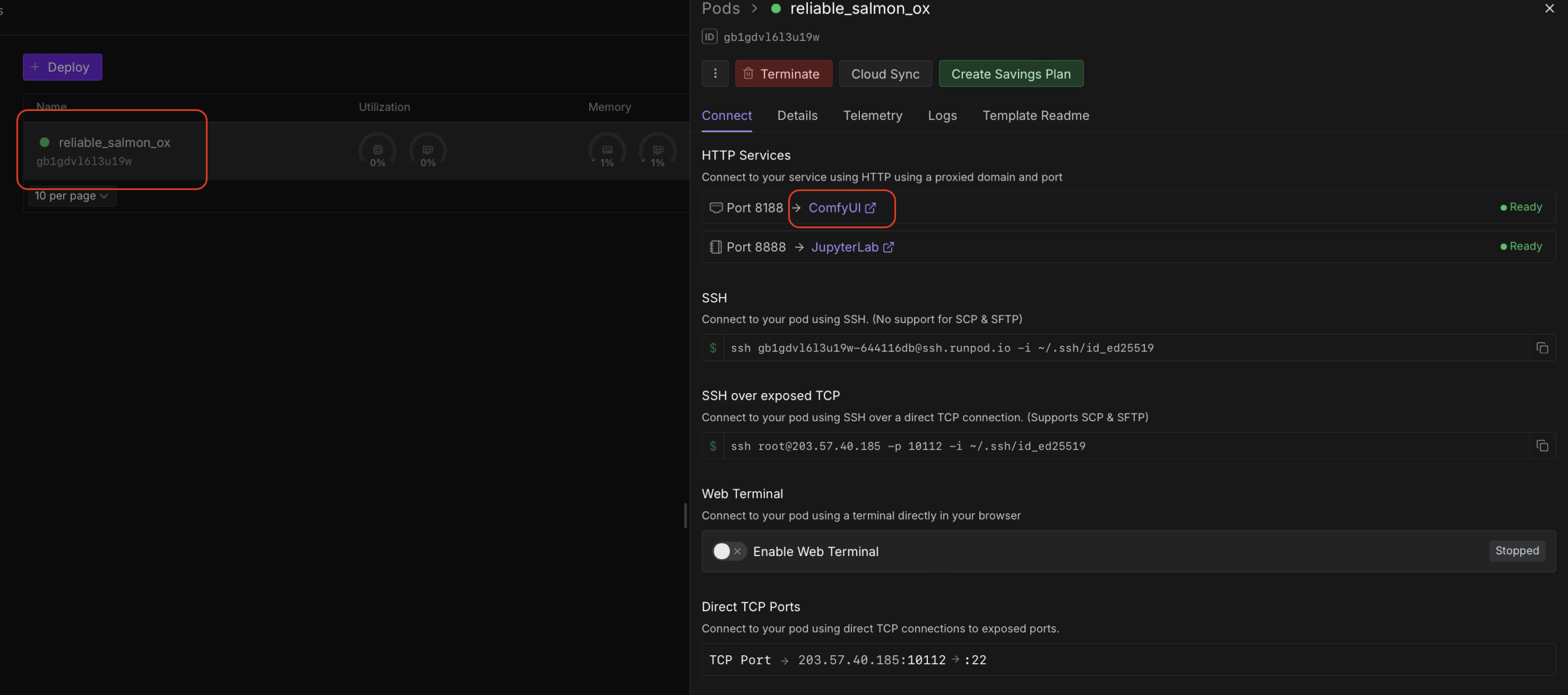
Чтобы запустить графический интерфейс ComfyUI необходимо зайти в наш под в runpod и нажать на ссылку ComfyUI:
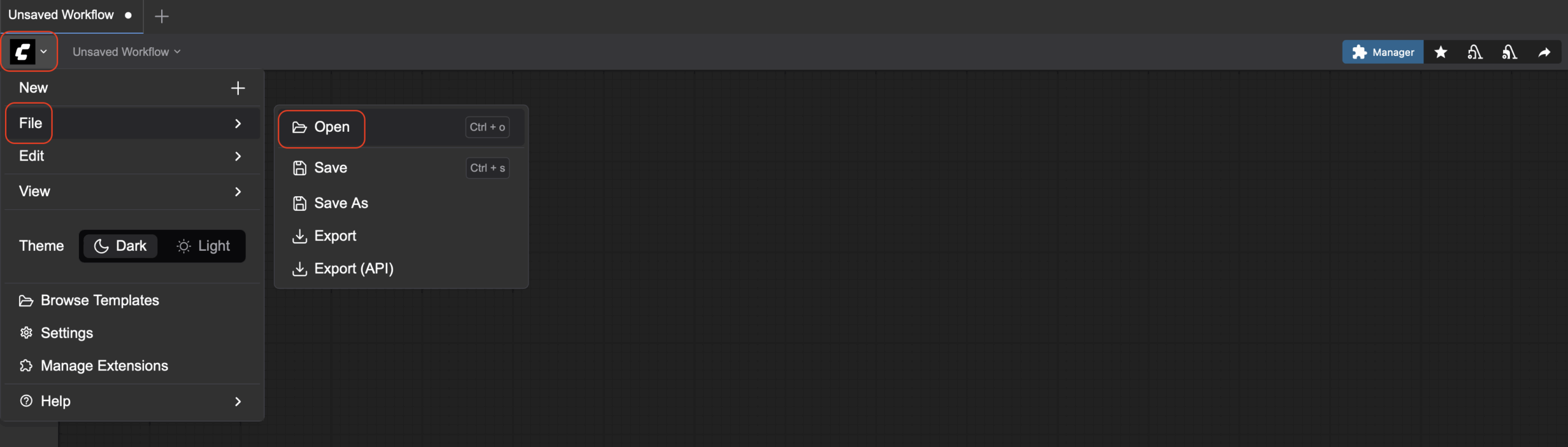
После этого откроется стартовое окно ComfyUI с разными template, нам они не нужны, закрываем. Скачиваем на свой комп Workflow. Открываем этот файл:
При первом запуске запросит установить дополнительные ноды:
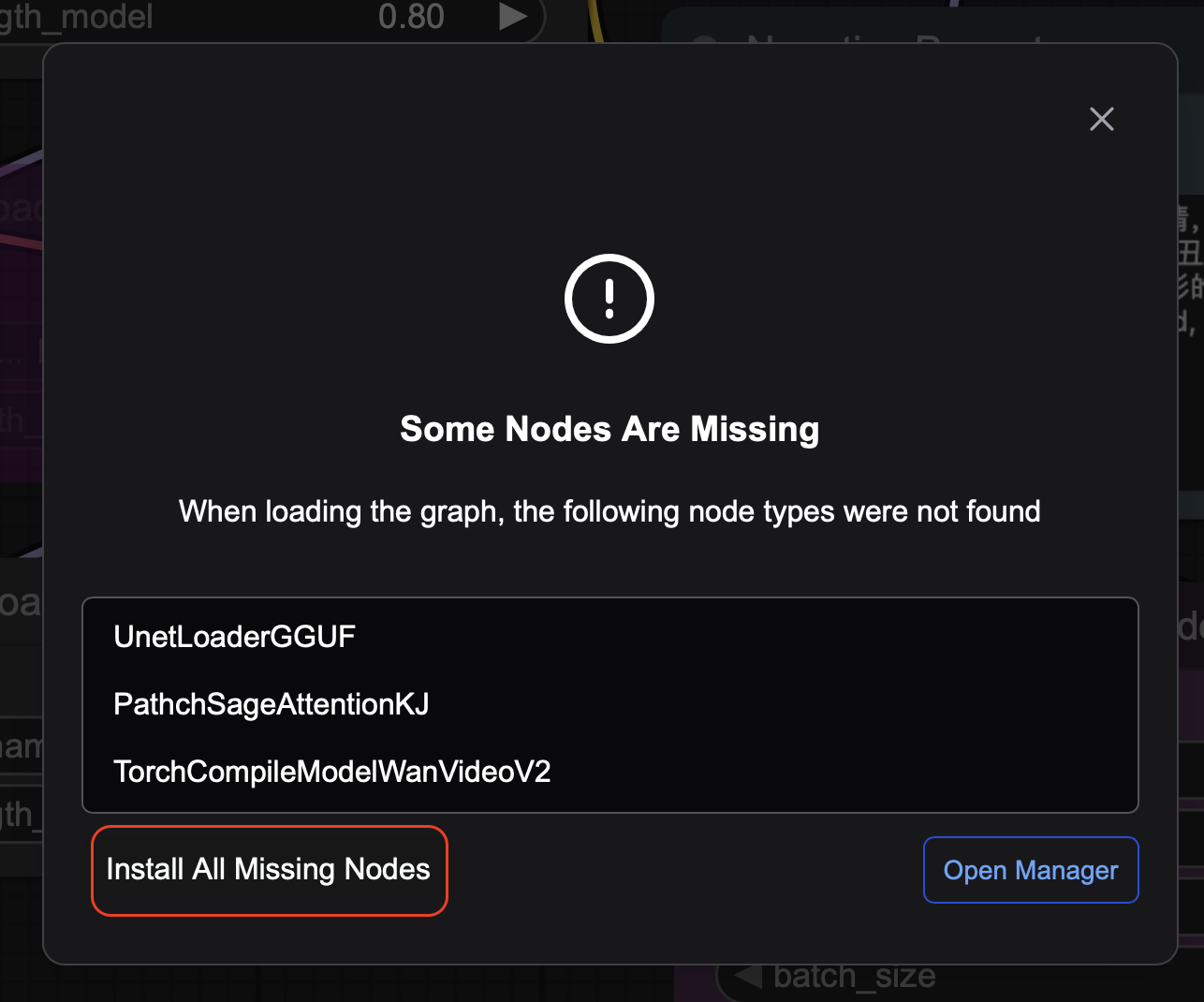
Жмем Install All Missing Nodes. После установки жмем restart и обновляем страницу в браузере. Так же нам понадобится установить RES4LYF. Для этого открываем Manager и в открывшемся окне жмем Custom nodes manager:
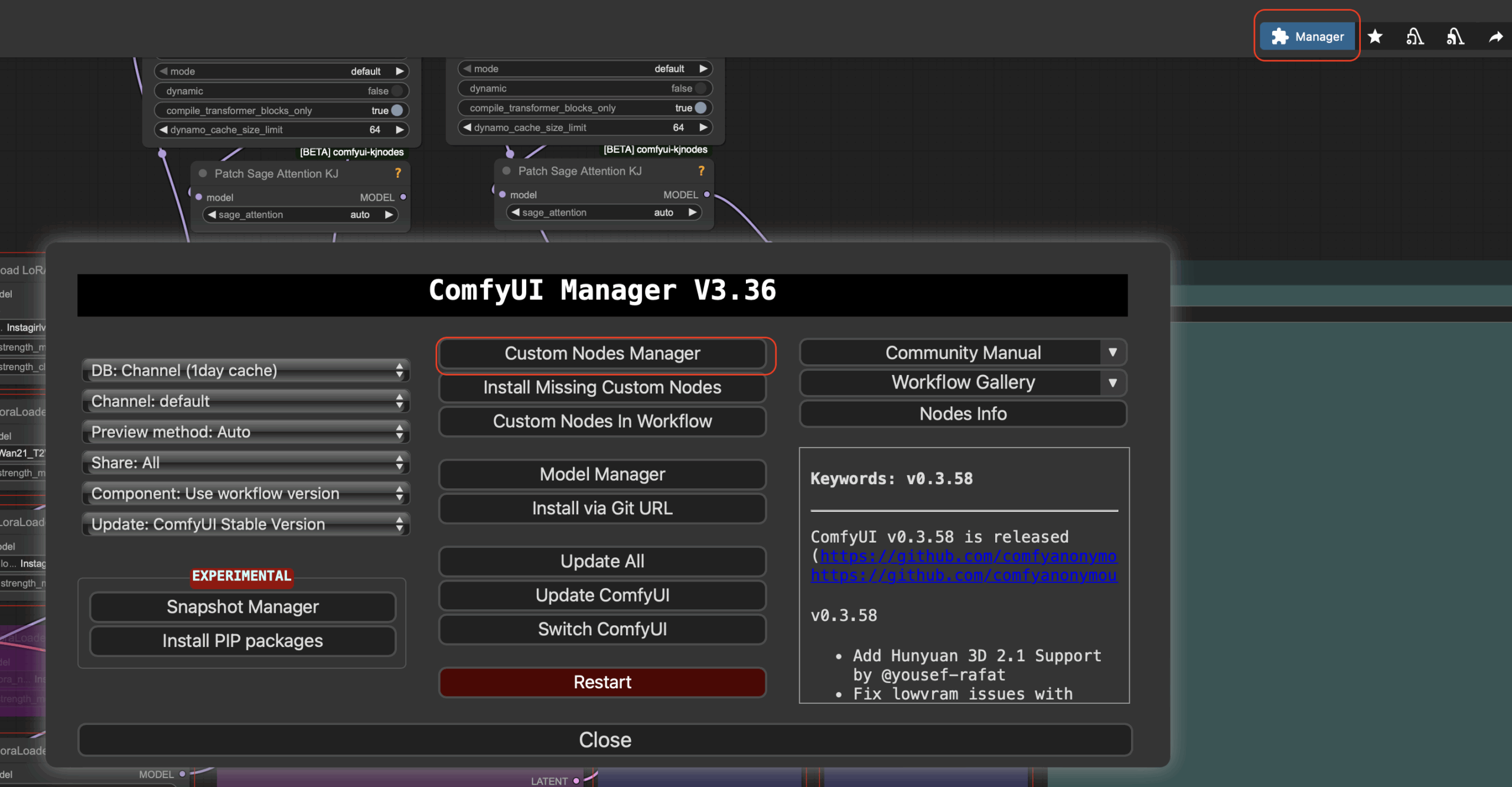
Далее в поиске вбиваем RES4LYF и жмем install потом выйдет окошко выбора версии, просто жмем select:
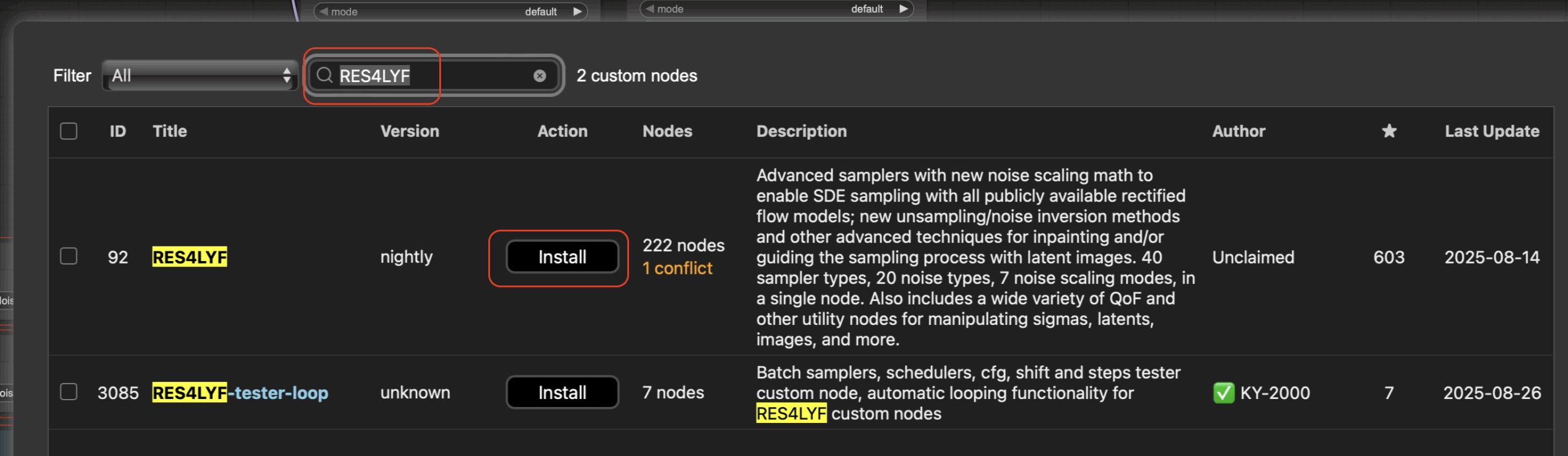
После окончании установки жмем кнопку restart и обновляем страницу в браузере пока не появится интерфейс ComfyUI.
Переходим обратно в JupiterLab. Теперь нам необходимо добавить файлы в папки Vae, Unet, Loras, Checkpoints, Clip. Список файлов которые нам необходимы находятся ниже.
Vae: wan_2.1_vae.safetensors
Unet: Wan2.2-T2V-A14B-HighNoise-Q8_0.gguf | Wan2.2-T2V-A14B-LowNoise-Q8_0.gguf
Loras: Instagirlv2.5-HIGH.safetensors (Google drive) | Instagirlv2.5-LOW.safetensors (Google drive) | Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors | Lenovo.safetensors (Google drive)
Checkpoints: WAN2.2-HighNoise_SmartphoneSnapshotPhotoReality_v3_by-AI_Characters.safetensors
Clip: umt5_xxl_fp8_e4m3fn_scaled.safetensors
Ссылки кликабельны. Некоторые файлы мы будем перекачивать по прямой ссылке из huggingface с помощью команды wget. Ссылки помеченные Google drive будем скачивать с помощью команды gdown —fuzzy. Для примера перакачаем из huggingface файл в папку vae. Открываем терминал:
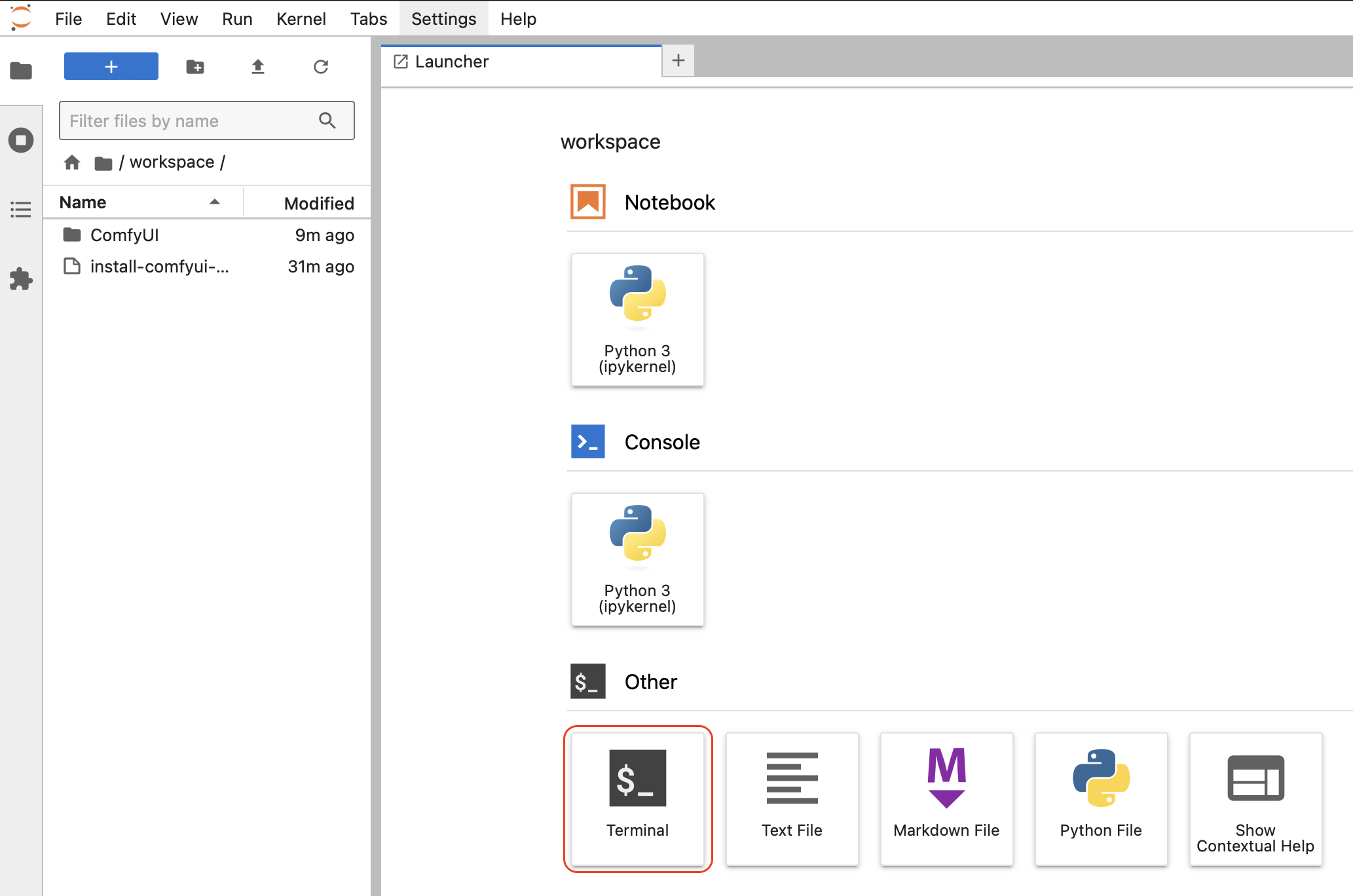
После того как терминал запустится, с помощью команды cd переходим к директории ComfyUI/models/vae
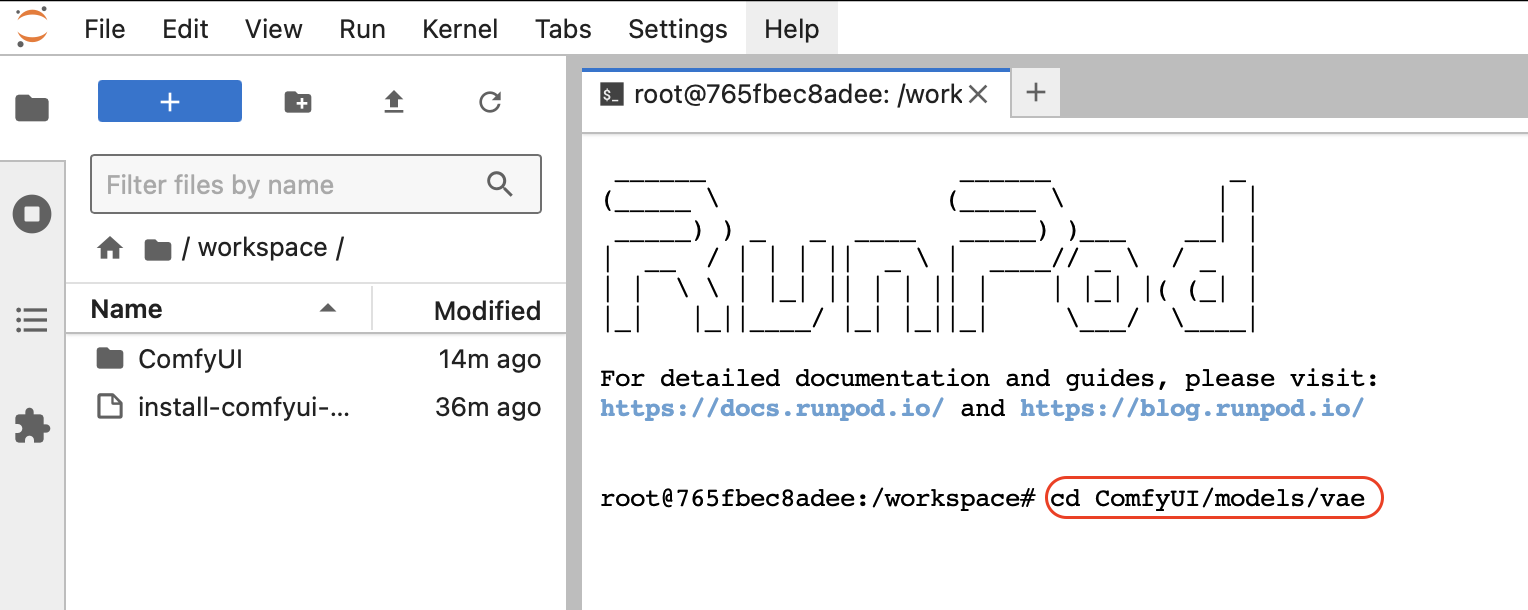
Жмем Enter и выполнится переход. Далее нам надо скопировать прямую ссылку на наш файл из huggingface. Переходим на wan_2.1_vae.safetensors и жмем Copy download link:
Мы скопировали прямую ссылку для скачивания, сейчас нам надо вернуться обратно в терминал и скачать наш файл с помощью команды wget, пишем команду и после пробела вставляем нашу ссылку для скачивания:

Жмем Enter и ждем скачивания. В итоге мы должны увидеть это:

Это означает что наш файл успешно загружен. Проверим наличие нашего файла. Проверим наличие нашего файла с помощью команды ls -l

Как мы видим, файл находится в данной директории. Сейчас мы будем с помощью терминала переходить по директориям и скачивать туда нужные файлы. Сейчас мы находимся в папке vae. Чтобы нам перейти назад в папку models используем команду cd ..

Мы перешли в папку models. Так как остальные нужные папки у нас находятся в папке models, для перехода мы будем использовать команду cd {название папки}. Например для перехода в папку unet, необходимо использовать команду cd unet. По аналогии перекачиваем наши файлы в целевые папки. Загружать файлы на которых нет прямой ссылки мы будем из Google Drive . Например для Instagirlv2.5-HIGH.safetensors копируем ссылку, переходим в директорию loras и вводим команду gdown —fuzzy «https://drive.google.com/file/d/1wJQl65Y7Ke2iDVeMdYqAZTMiCnpWPXTC/view?usp=share_link»
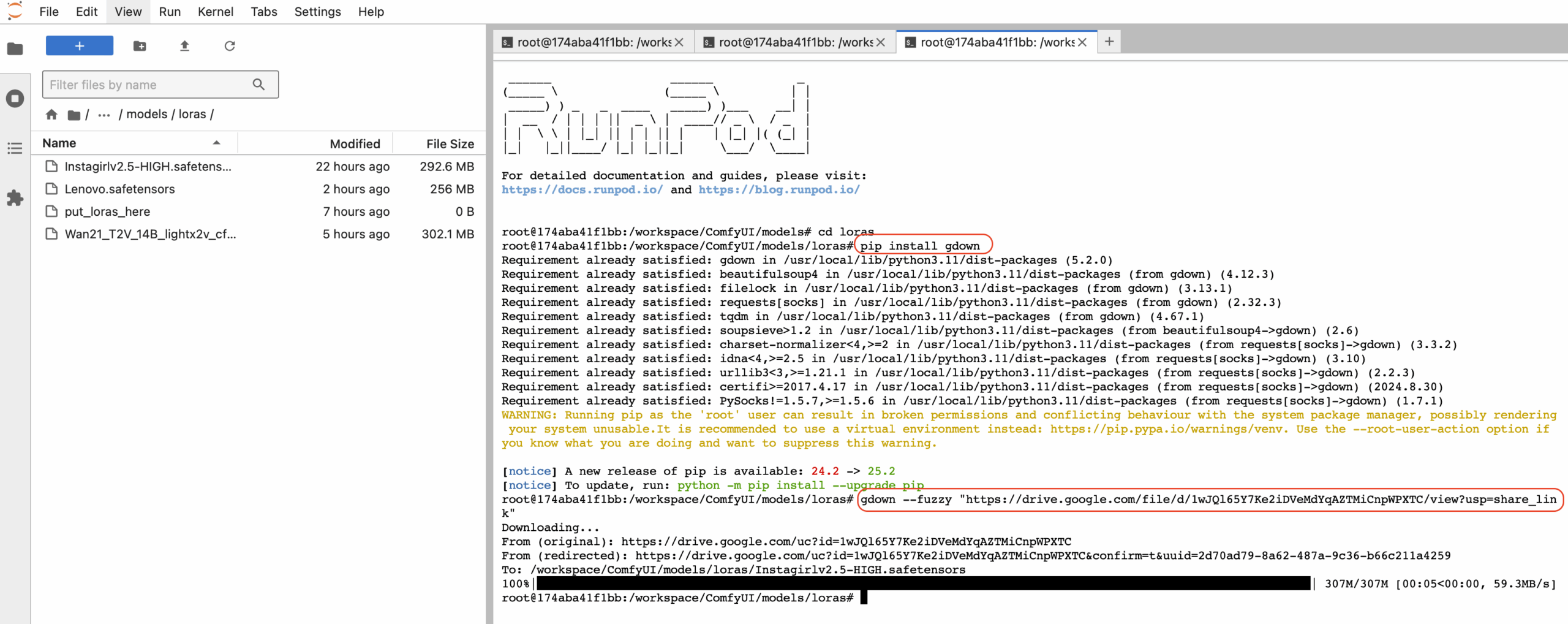
Ждем окончания загрузки. Проделываем это для остальных файлов из Google drive меняя ссылку в команде.
Теперь убеждаемся что все нужные файлы находятся в соответствующих папках и можно приступать к следующему этапу.
Первый запуск генерации
Открываем терминал в Jupiterlab и с директории /workspace выполняем команду ./run_gpu.sh
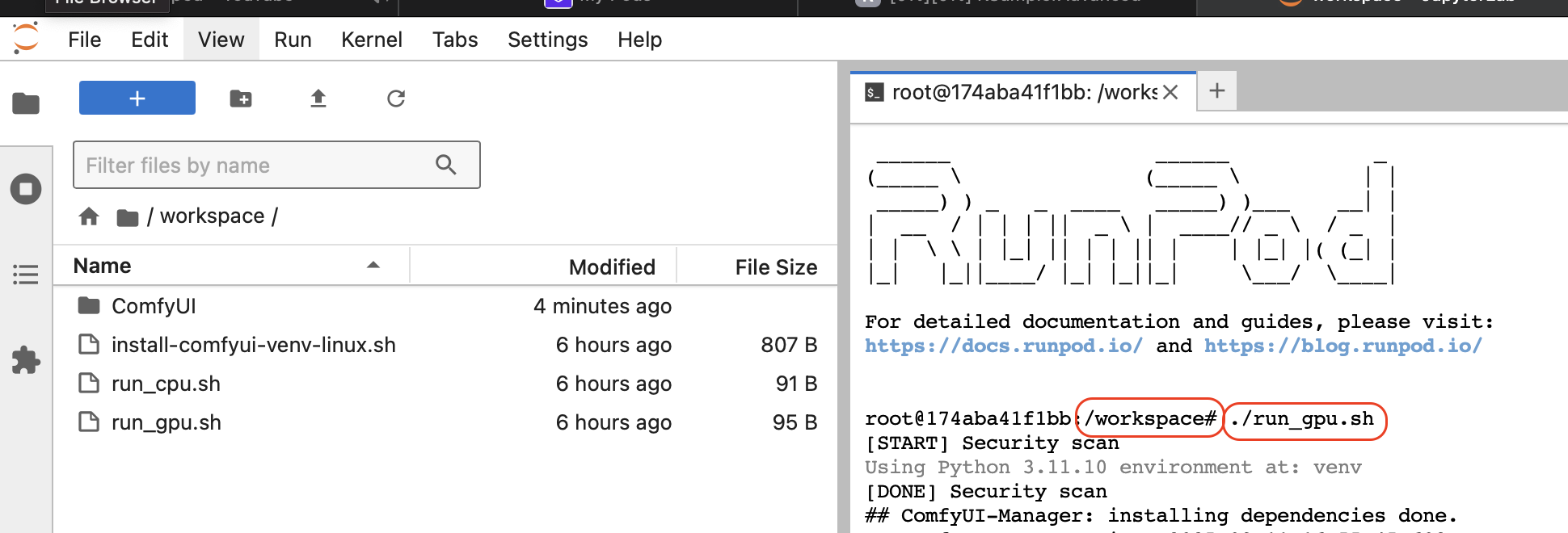
Ждем запуска ComfyUI и выхода сообщения в логе [ComfyUI-Manager] All startup tasks have been completed. После этого можем запускать наш ComfyUI в меню Pods:
После открытия ComfyUI опять открываем наш Workflow:
Делаем первый запуск генерации нажав на Run внизу окна:
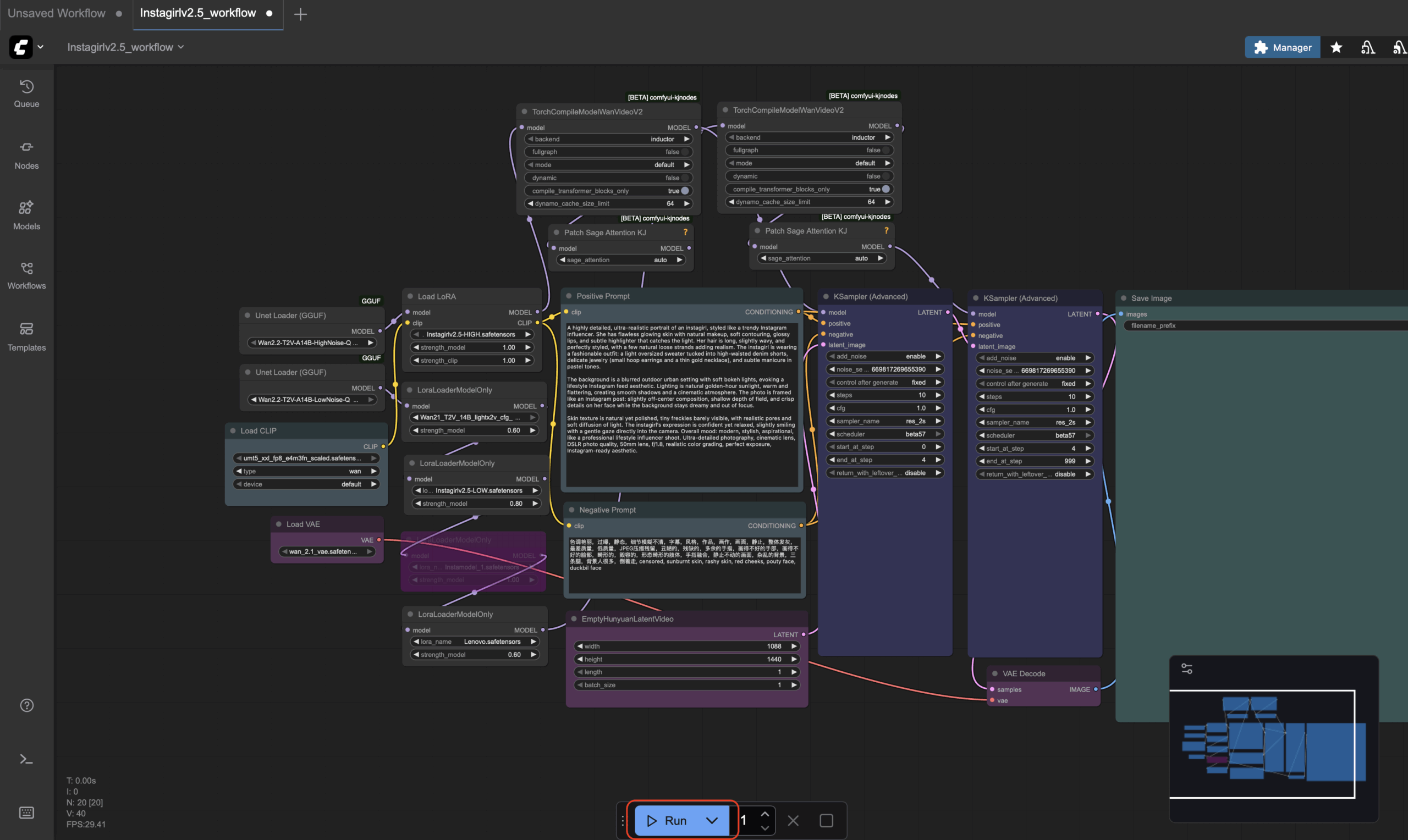
Запустится генерация изображения. Первая генерация происходит долго из-за подгрузки моделей (может занять 4-5 минут). При этом в JupiterLab можно смотреть в логах процесс генерации. Если выйдет окно с ошибкой который содержит название файла, то вы скорее всего забыли перекачать файл в нужную папку. Если все хорошо увидим картину:
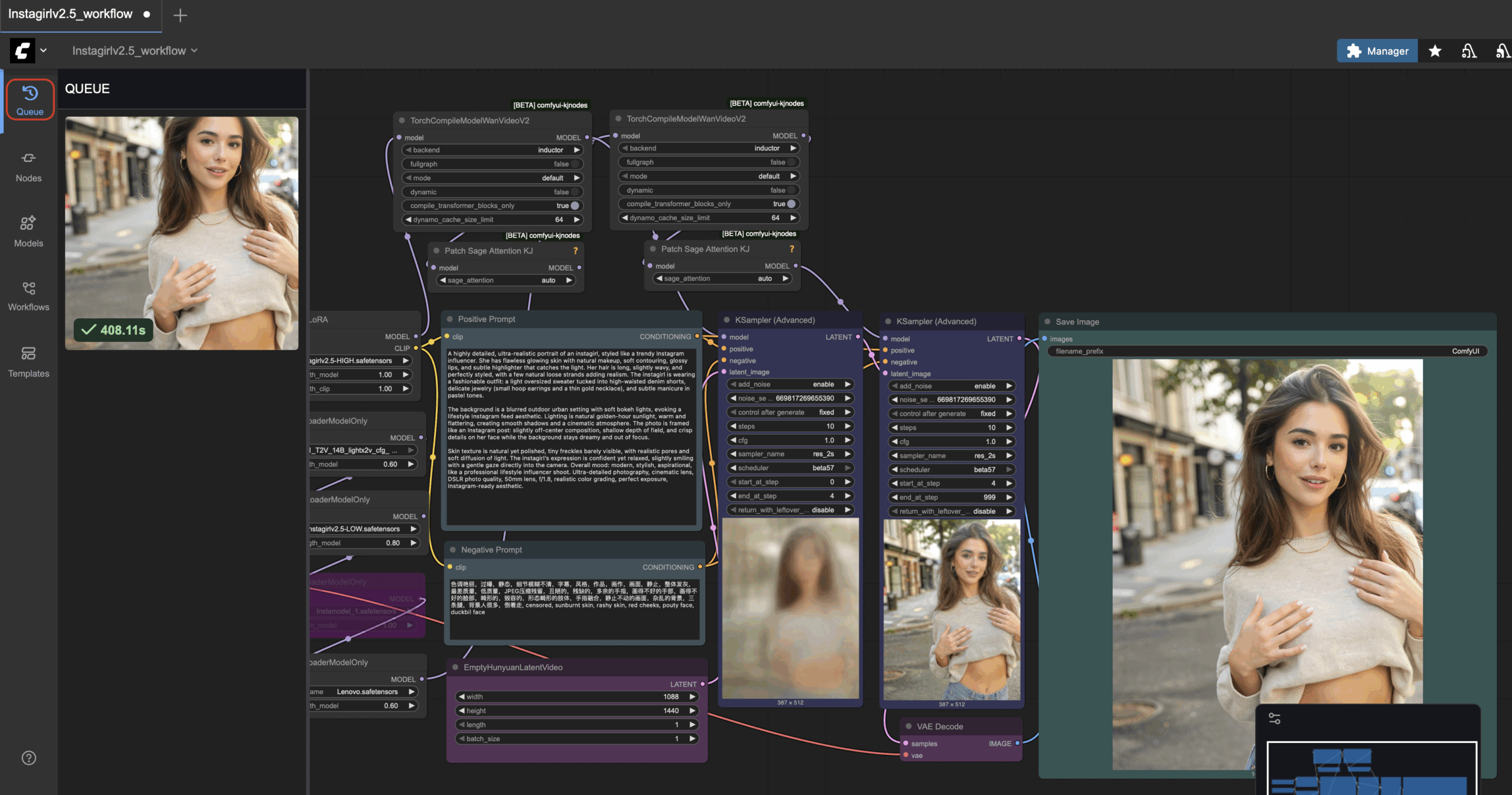
Промпты необходимо вводить в окно Positive prompt:
Промптинг
В любой нейросети промпты играют важную роль для получения результата. В данном случае у нас должны быть positive и negative промпты. Positive отображает то что вы хотите получить. Negative, соответсвенно чего вы не хотите.
Пример промпта для нашего случая:
Positive: Instagirl, a young woman with her hair in two high pigtails, dyed half lavender and half mint green, she is winking one eye at the camera and giving a peace sign right next to her cheek, a wide, playful smile on her face, wearing a white collared shirt with a black ribbon tie, tight close-up selfie, taken from a slightly high angle in her bedroom, the background is a collage of anime posters and photos taped to the wall, ring light reflection, high angle selfie, Instagirl, kept delicate noise texture, dangerous charm, amateur cellphone quality, visible sensor noise, heavy HDR glow, amateur photo, blown-out highlight from the lamp, deeply crushed shadows
В нашем workflow используется лора Instagirl, поэтому генерируемого человека мы должны обозначить как Instagirl.
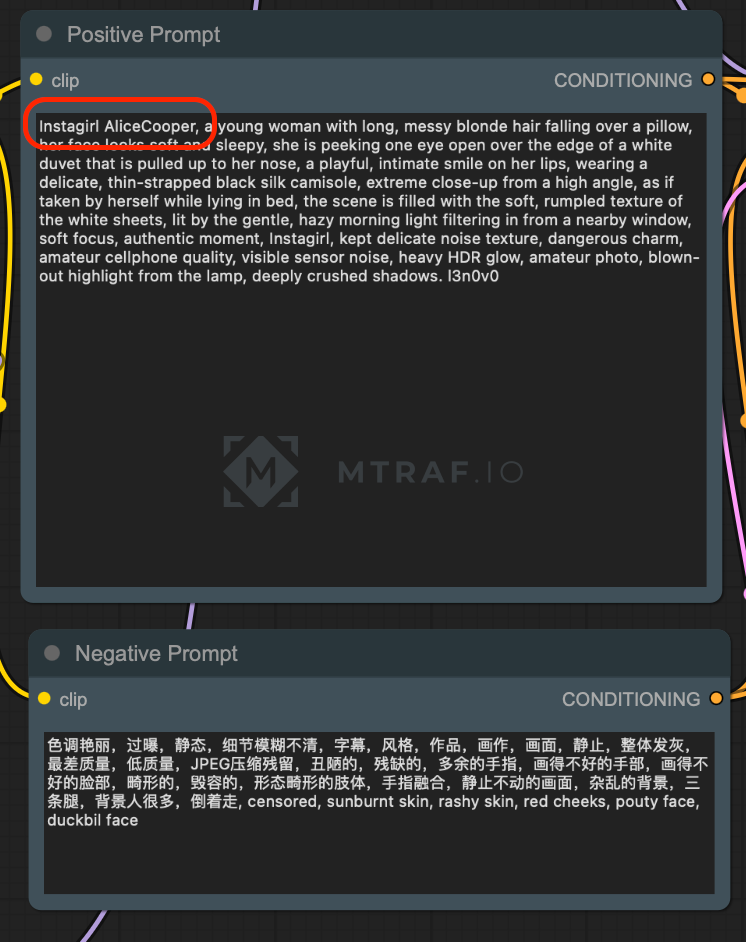
Negative: 色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走, censored, sunburnt skin, rashy skin, red cheeks
В негативном промоет можно дописать то что вы не хотите видеть (например можно запретить генерировать других людей, тексты и тд)
Самый удобный способ написать промпт это использовать для этого нейросеть. Пишем на русском что мы хотим получить и показываем пример промпта:

Текст промпта из этого примера: сделай промпт на английском для генерации изображения девушки. обязательно используй слово instagirl для определения девушки: девушка сидит на кровати в красном платье. Сделай объемный промпт с большим количеством деталей. Пример: Instagirl, a young woman with her hair in two high pigtails, dyed half lavender and half mint green, she is winking one eye at the camera and giving a peace sign right next to her cheek, a wide, playful smile on her face, wearing a white collared shirt with a black ribbon tie, tight close-up selfie, taken from a slightly high angle in her bedroom, the background is a collage of anime posters and photos taped to the wall, ring light reflection, high angle selfie, Instagirl, kept delicate noise texture, dangerous charm, amateur cellphone quality, visible sensor noise, heavy HDR glow, amateur photo, blown-out highlight from the lamp, deeply crushed shadows
Для промптинга более откровенных изображений необходимо использовать uncensored текстовые модели, например Venice: Uncensored (free)
Правильная остановка работы
Для остановки работы необходим закрыть окно с ComfyUI и в меню Pod нажать на кнопку Terminate:
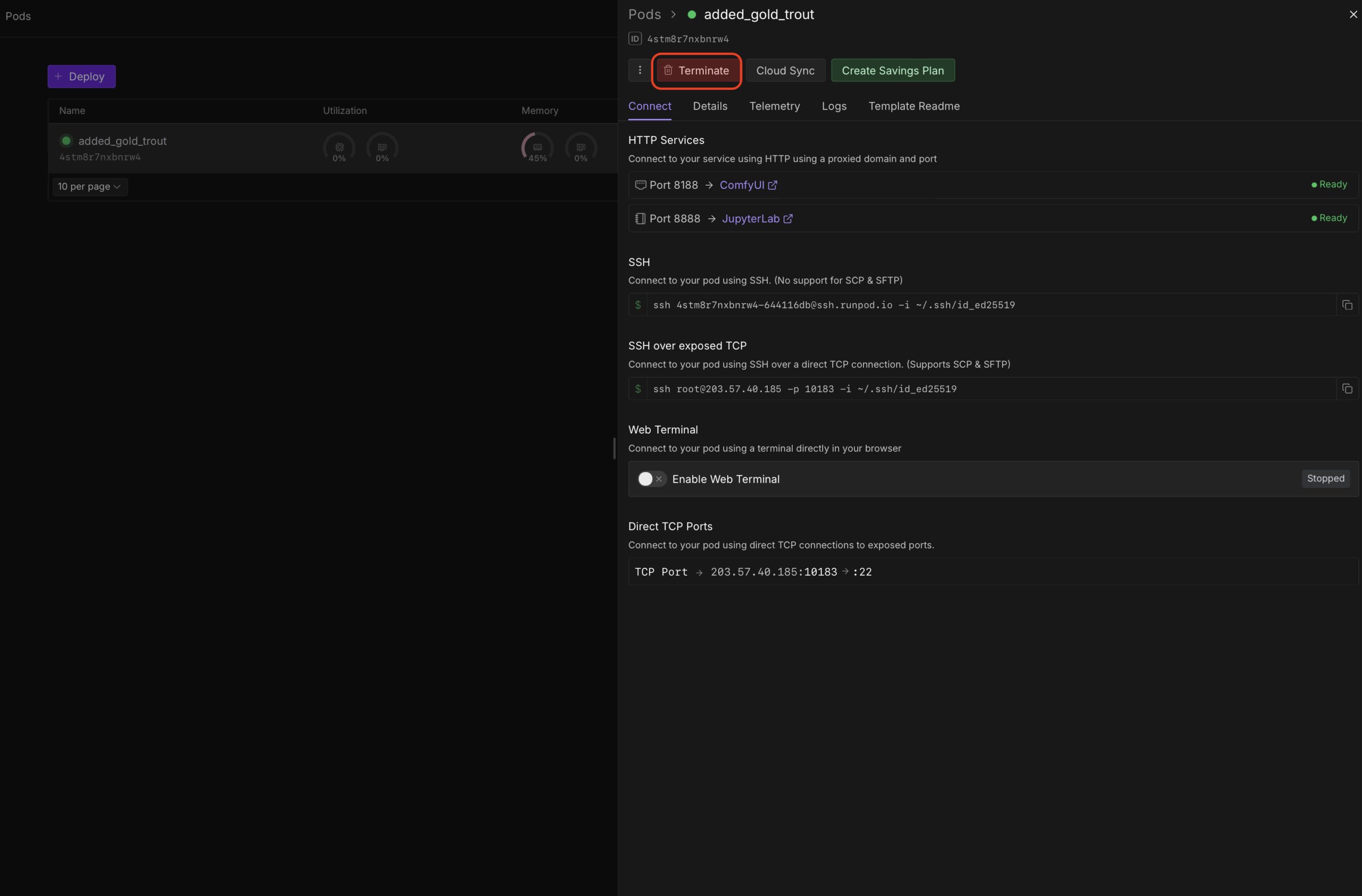
При этом остановится наш сервер, но данные наши сохранятся в хранилище.
Обучение Lora для генерации изображения на Wan 2.2 (Instagirl)
Это второй урок по генерации изображений с помощью модели Wan 2.2 используя ComfyUI. На первом уроке мы запустили арендованный сервер с GPU и разобрались с генерацией изображений (данный урок предполагает что вы изучили первый урок). Но при генерации изображений мы получали разных людей. В этом уроке мы будем тренировать Lora с помощью арендованного сервера и удобного инструмента Ostris AI Toolkit.

Подготовка датасета
70% успеха в любом обучении нейросетей является качество датасета, набора входных данных. В данном уроке нам надо будет сделать набор датасета который будет составлять пару изображение+текстовый промпт. Генерировать изображения для датасета мы будем с помощью модели Nano Banana подав на вход изображение референса (оригинальное изображение человека которое вы хотите обучить). Правило для референса: лицо должно быть видно четко, без перекрытия волосами, руками и тенями. Для доступа к nano banana я использовал Openrouter. И так, какие изображения нам надо получить: крупные планы лица под разными углами, разные эмоции на лице, разные позы (сидя, стоя, лежа), разные обстановки. При этом для выходных изображений тоже необходимо придерживаться правил: четкое лицо без перекрытия, сохранение прически, желательно нейтральный минималистичный фон. Примеры промтов вы можете посмотреть в файле. Для обучения нам необходимо от 10-20 фотографий, чем больше тем лучше. Но при этом увеличивается время и стоимость обучения. Пример моего датасета на который вы можете ориентироваться (обратите внимание на названия файлов, AliceCooper в моем случае это активационный тег, уникальное слово для обучения и активации Lora модели после обучения, этот тег вы можете придумать сами). После генерации набора изображений нам необходимо для них сгенерировать короткое описание. Для этого я использовал ChatGpt. Пример промпта: These are photos of AliceCooper, analyze those images and caption them correctly for a lora training using «AliceCooper» as the caption token and convert each single caption into a txt file and name them all in the same order, AliceCooper_01.txt, AliceCooper_02.txt, etc and then finally zip them all into a zip file so I can download it.
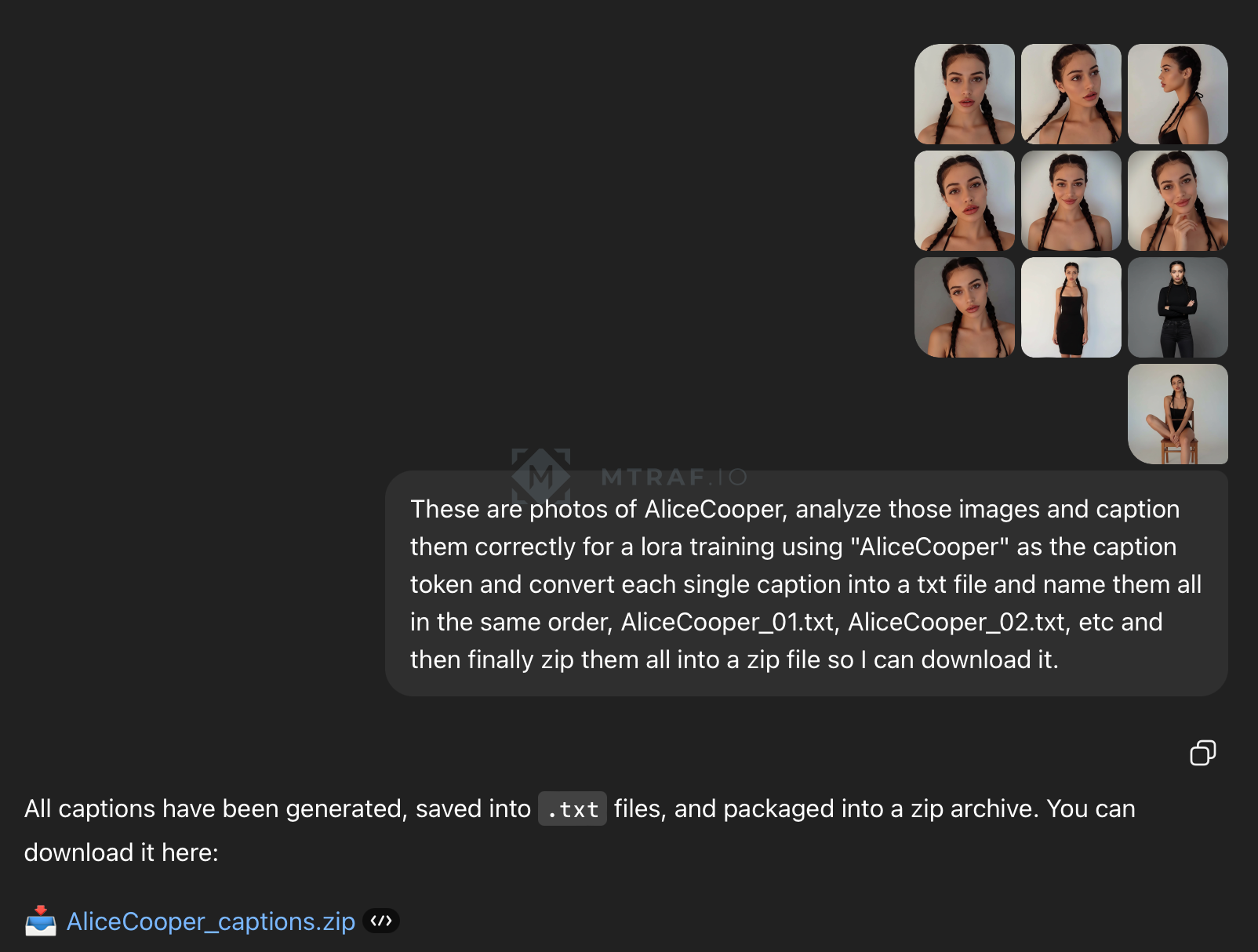
На выходе получаем уже архив с описаниями в текстовых файлах (ВАЖНО, убедитесь что пара изображение+текстовое описание подходят друг другу, например: текстовый файл AliceCooper_01.txt описывает изображение AliceCooper_01.png). После того как наш дотаяет готов нам необходимо сделать 10 проверочных промптов, по которым во время обучения периодически будут генерироваться изображения и по которым мы сможем наблюдать за прогрессом обучения. Генерировать будем с помощью того же ChatGpt. Промпт: Сделай 10 промптов на английском для генерации изображения девушки в различных ситуациях и позах. Для обозначения девушки используй слово AliceCooper.

Запуск сервера с GPU и обучения на AI Toolkit
На прошлом уроке мы использовали мощности Runpod, но меня перестала устраивать их недоступность GPU и лаги при работе. Поэтому в этом уроке мы будем использовать Vast.ai (реф). Для доступа необходим зарубежный ip адрес и карта для оплаты. Регистрируемся и пополняемся хотябы на 10$ (пополнение на вкладке billing). После пополнения переходим во вкладку Instances и нажимаем Create Instance.
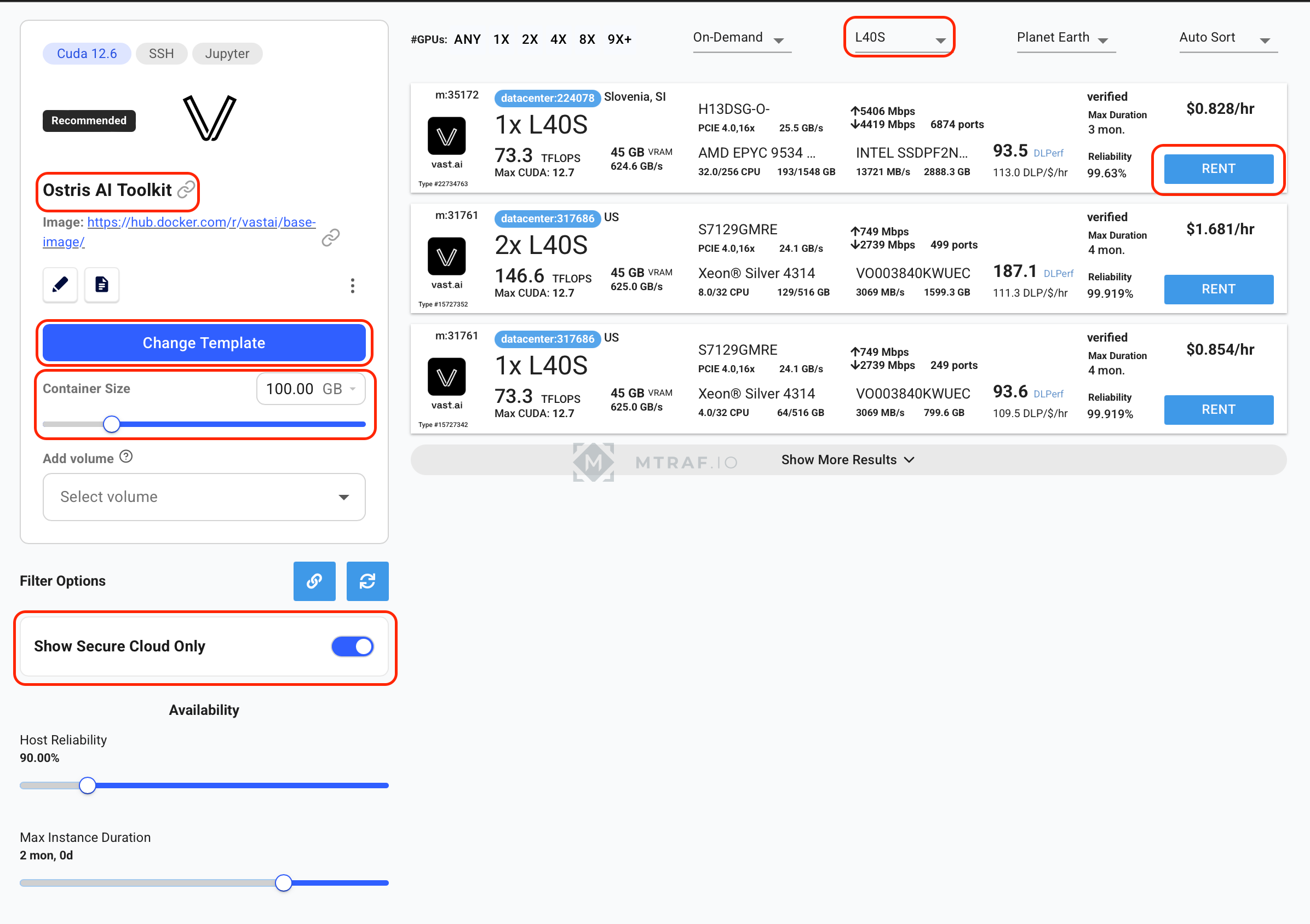
Здесь жмем Change template и выбираем Ostris AI Toolkit. Container size 100 gb. Show Secure Cloud Only. В фильрах выбираем L40S, находим 1x L40S и жмем rent. Жмем опять Instances, ждем пока активируется кнопка Open и жмем его.
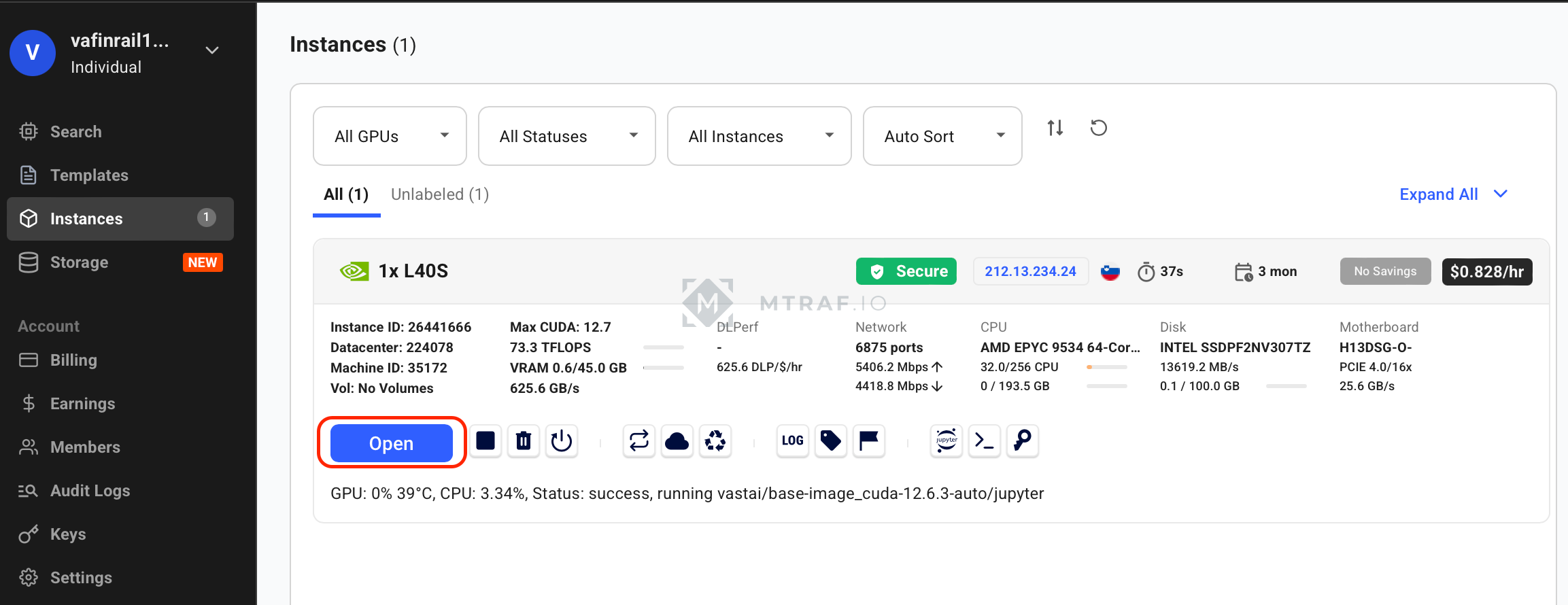
В появившемся окне жмем launch application у AI Toolkit
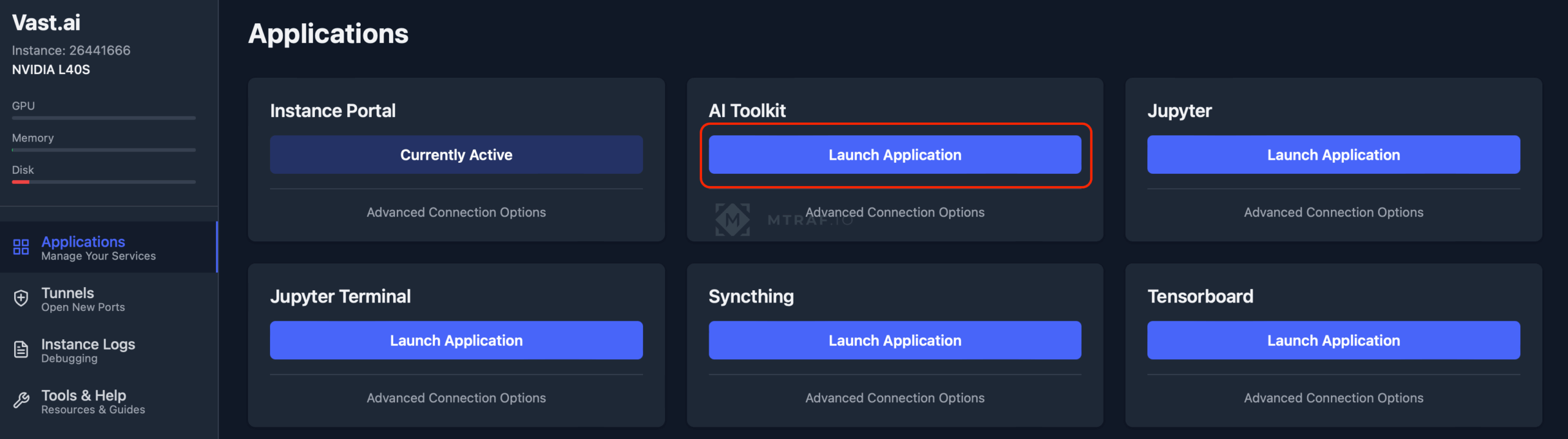
После того как Ai toolkit запустится (если просит пароль при входе, то просто введите password), переходим во вкладку Datasets и жмем New Dataset. В окне запроса имени фдатасета даем название совпадающее с тегом (в моем случае AliceCooper).

После создания фдатасета, жмем Add images и добавляем пары изображения+текстовые описания (смотри мой пример датасета).
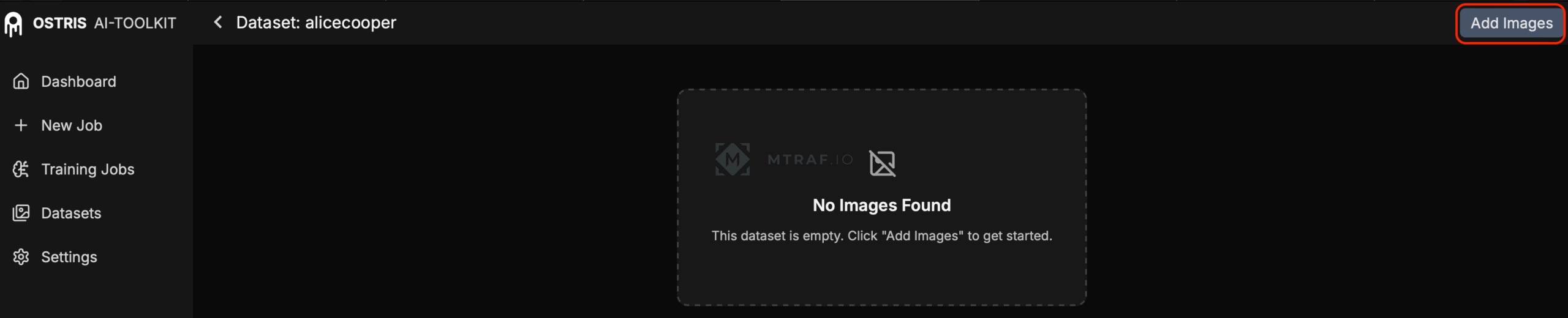
Если вы все правильно сделали появятся изображения уже с текстовыми описаниями (проверьте совпадают ли описания).

После того как наш датасет готов, переходим во вкладку New Job. Тут важно ввести правильно наш тег. Остальные параметры делаем такие как на скрине.
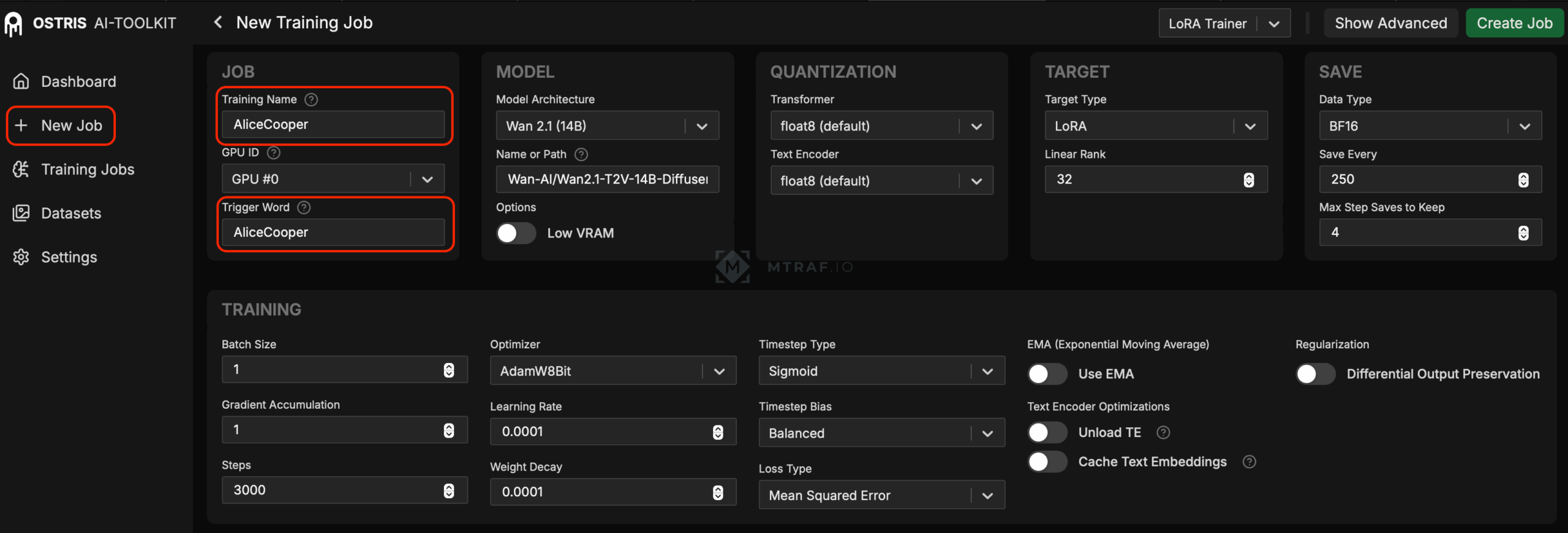
Листаем страницу вниз и выбираем нужные параметры. В sample prompts вводим 10 текстовых промптов, которые мы подготовили заранее.
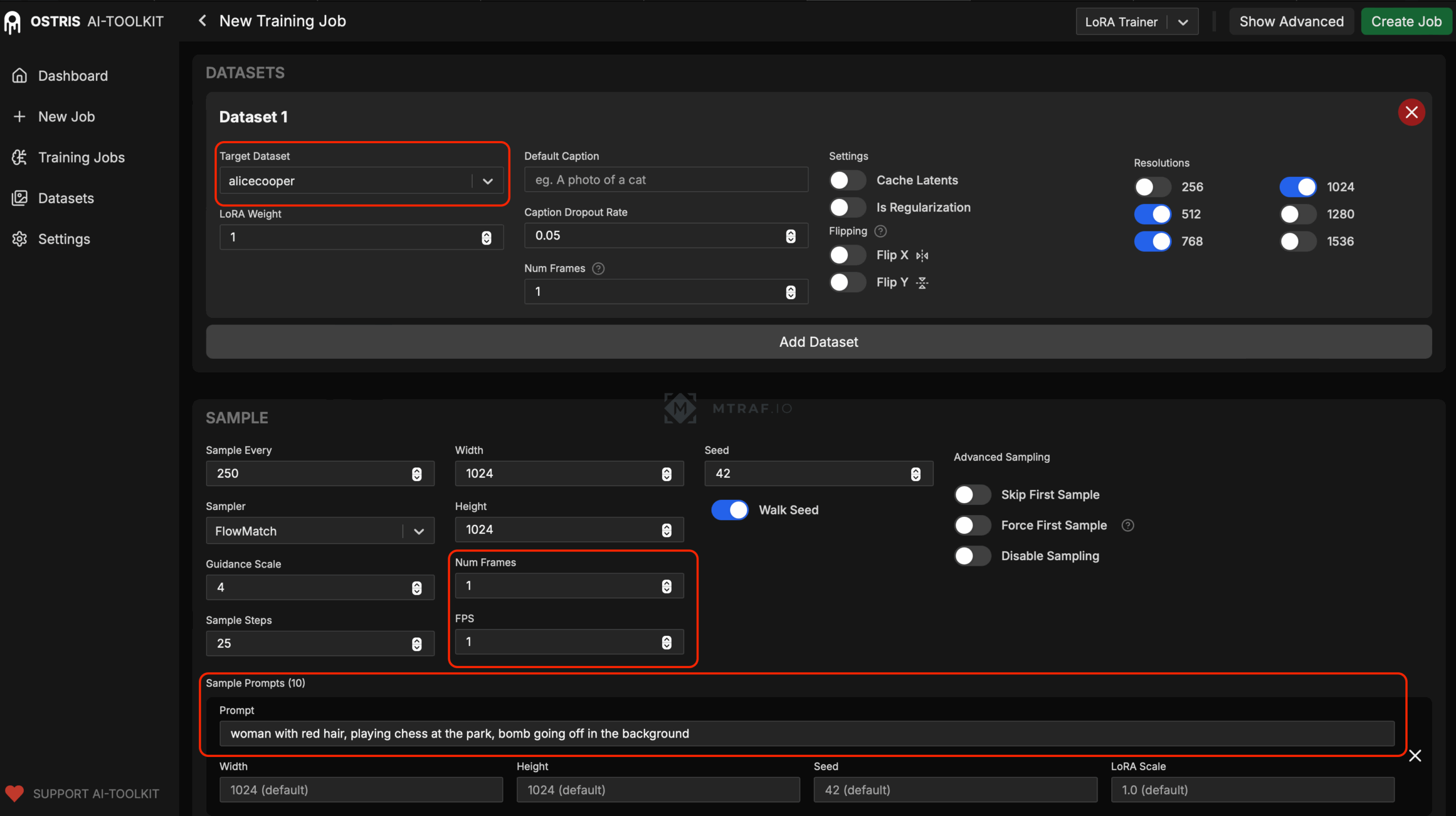
После заполнения всех данных жмем Create Job (на правом верхнем углу). Потом откроется окно с Job, его необходимо запустив нажав на кнопку ▶️.
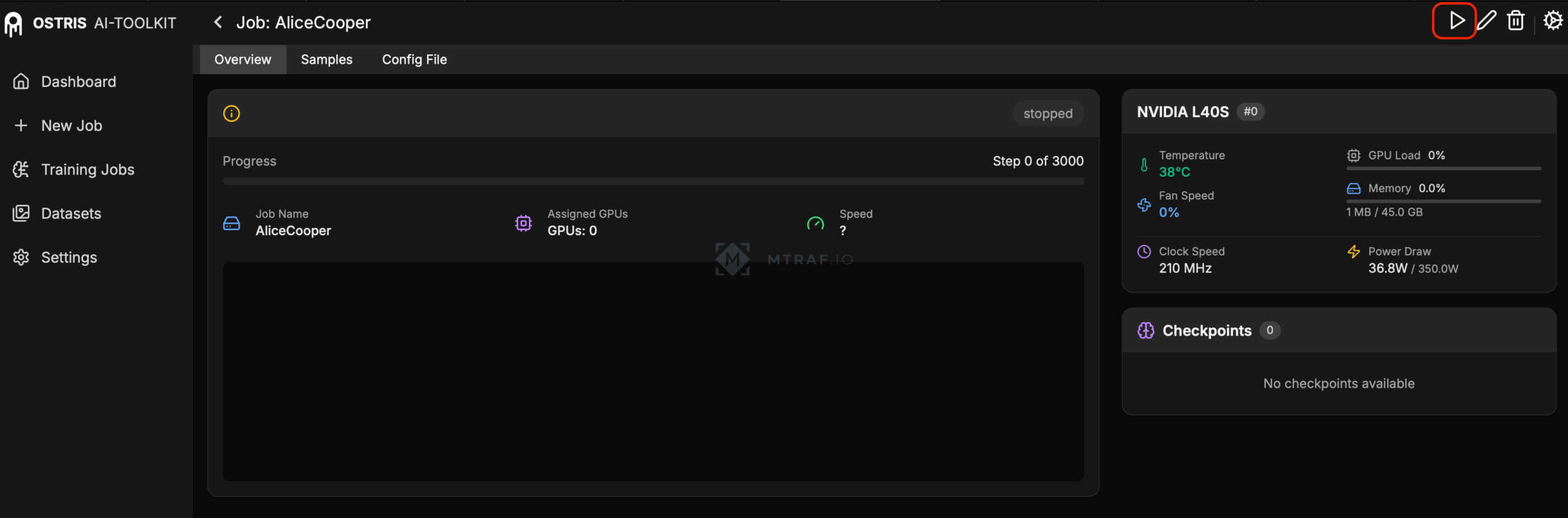
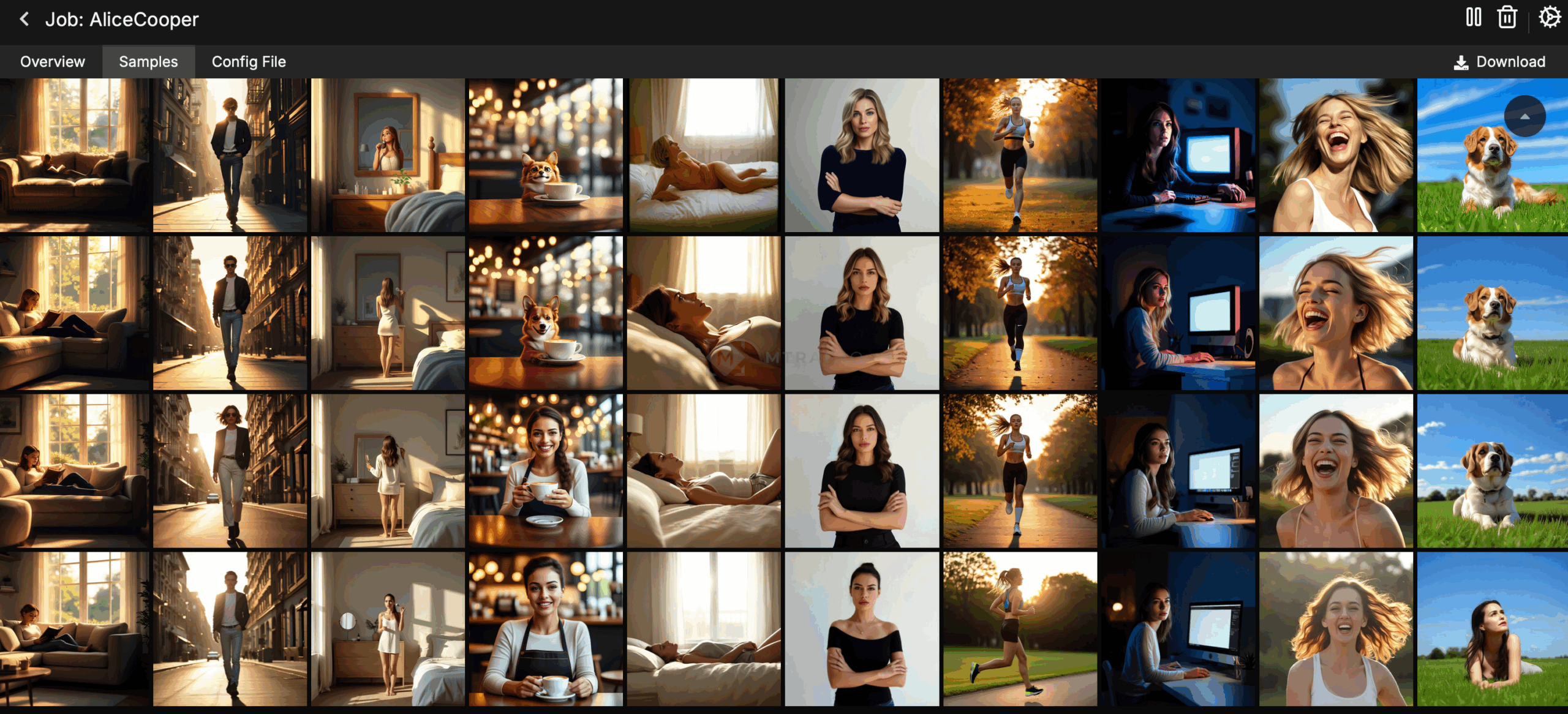
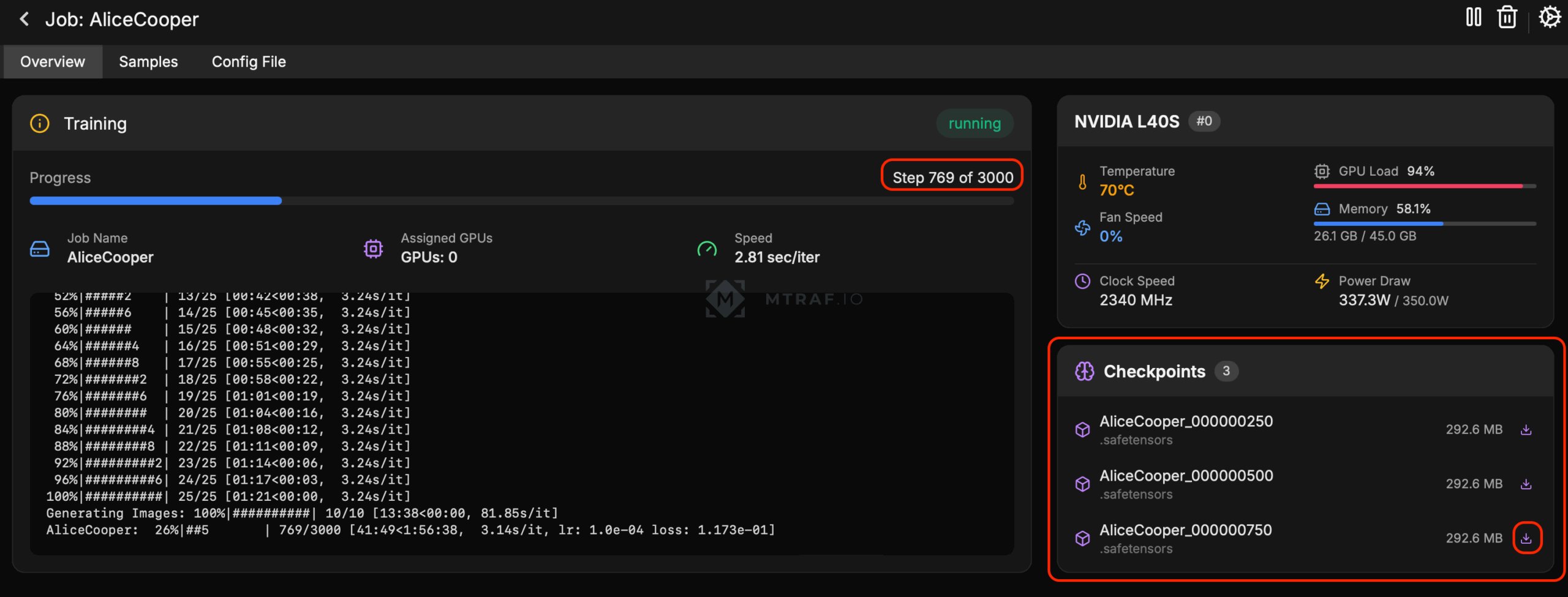
Наше обучение запустилось (сначала ai toolkit скачивает необходимые ему модели для обучения, на это уйдет некоторое время, смотри логи). Потом запустится сам процесс обучения, при этом мы все настроили так чтобы каждые 250 шагов нам генерировались тестовые изображения по нашим 10 промптам. Во вкладке samples мы можем посмотреть сгенерированные изображения после каждого 250-ого шага. Первые генерации будет далеко не похожи на оригинал, с каждым шагом изображения будут все больше схожи. Во вкладке Checkpoints каждые 250 шагов сохраняются чекпоинты (результат нашего обучения). Мы будем ждать главный чекпоинт после 3000 шага. Его необходимо будет сохранить на свой компьютер.
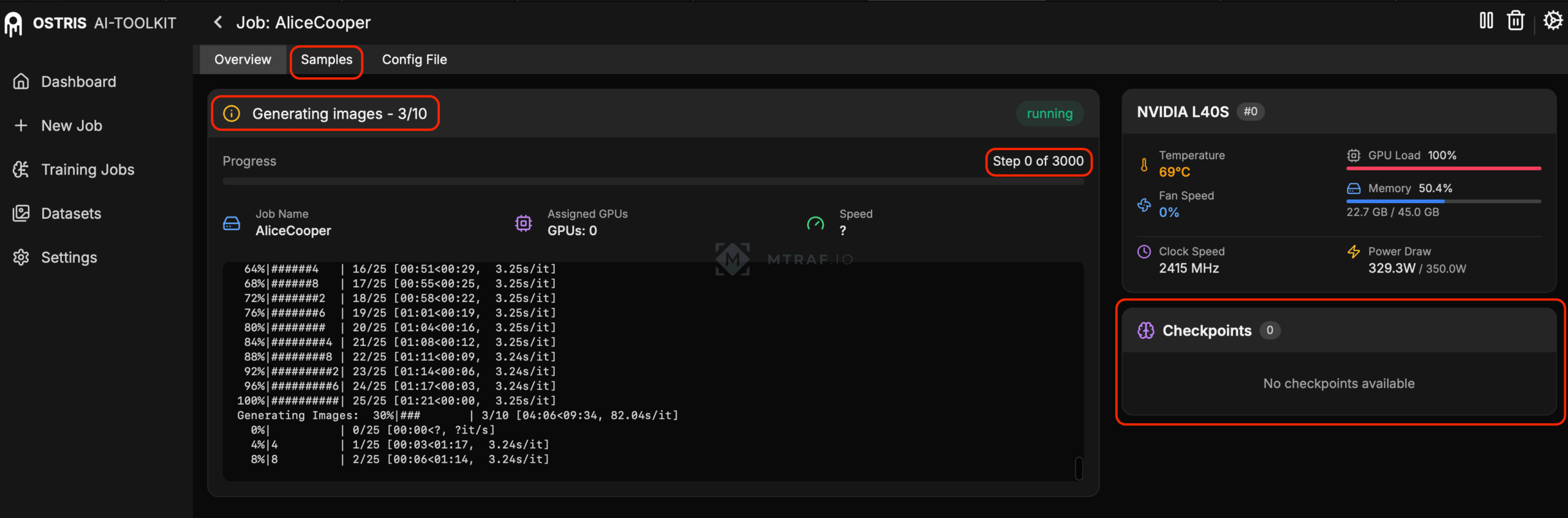
Далее мы сможем наблюдать как результаты становятся лучше и лучше.
Главный наш результат это получение файла AliceCooper.safetensors. Ждем пока выполнятся все 3000 шагов и появление файла AliceCooper.safetensors (без указания шагов на подобии 000000750, просто чистое название) в окне checkpoints и скачиваем этот файл на компьютер.
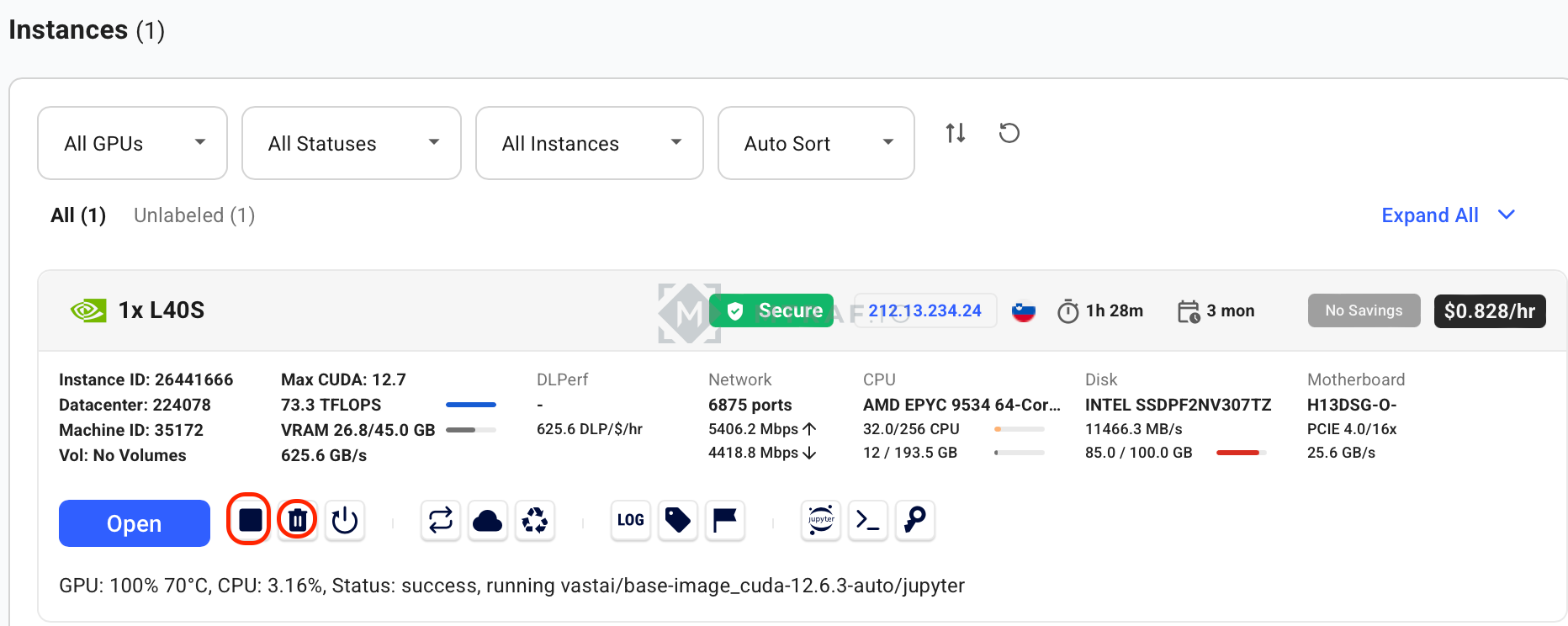
Завершение сеанса: у нас есть два вида завершения, остановка и удаление. В меню Instances жмем остановку, если мы хотим только приостановить работу (деньги будут списываться за хранилище) и полное удаление если не хотим больше использовать.
Генерация изображения с использованием нашей Lora
Для генерации изображения мы будем использовать этот воркфлоу. Для его запуска можно использовать прошлый урок c новый воркфлоу или следовать инструкциям которые будут далее. Создаем еще один Instance, при этом выбираем ComfyUI.
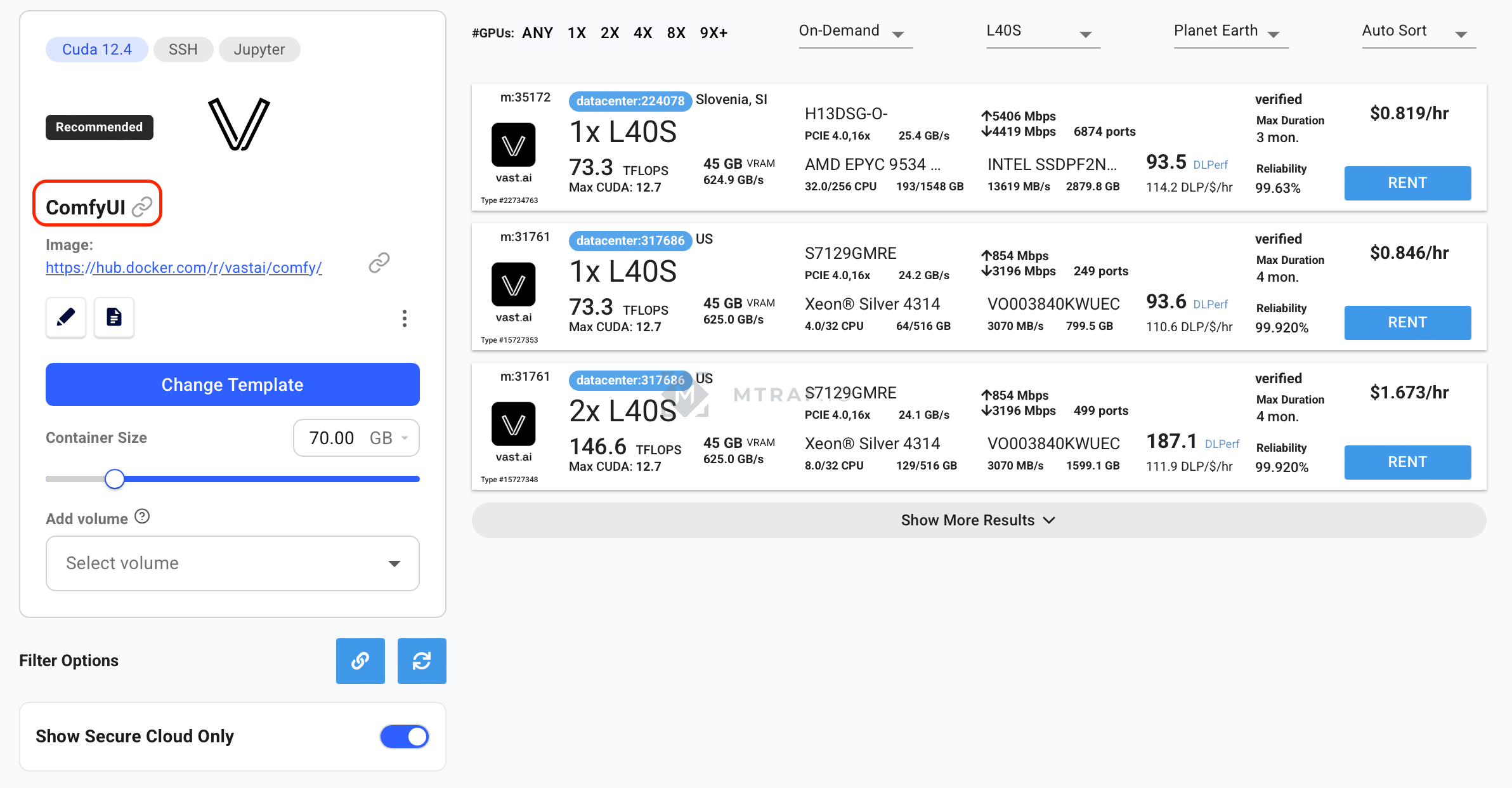
После запуска instance, нажимаем open и в меню выбора приложений нажимаем Launch Application для ComfyUI, Jupiter и Jupiter terminal. Перекачиваем все необходимые модели и custom nodes и RES4LYF (СМОТРИ ПЕРВЫЙ УРОК). Дополнительно придется перекинуть нашу обученную Lora в папку loras со своего компьютера (в моем случае это файл AliceCooper.safetensors).
Открываем воркфлоу в ComfyUI. Выбираем свою Lora в данной ноде (в моем случае AliceCooper.safetensors).
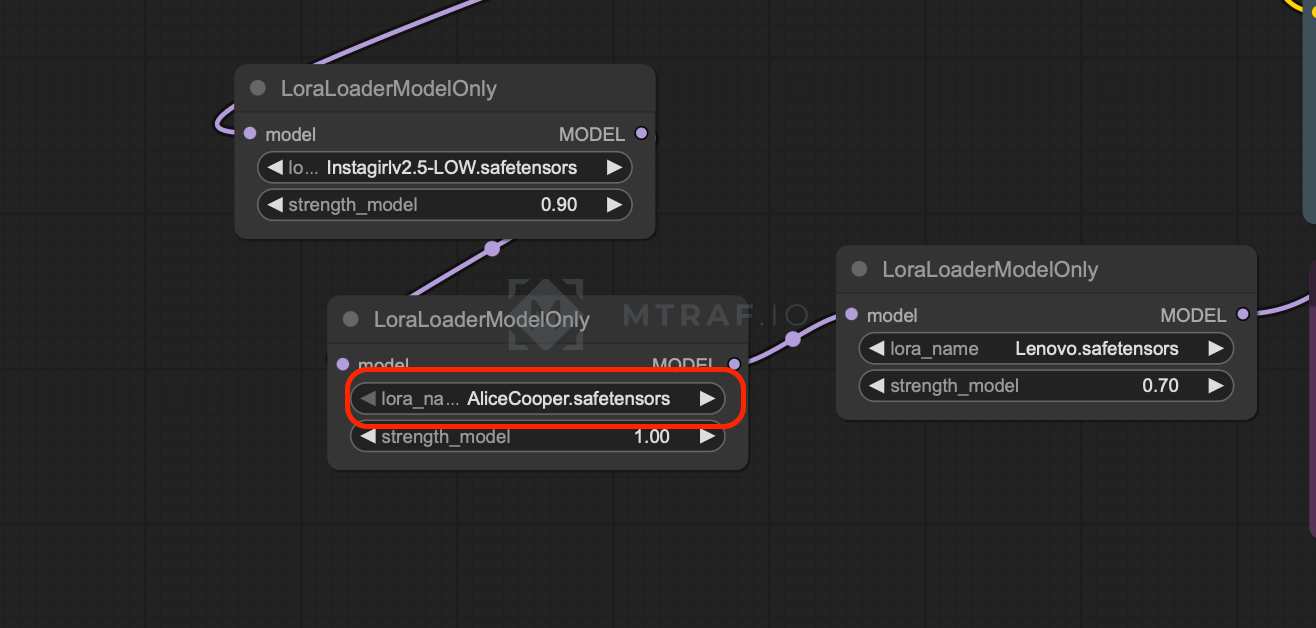
В ноде промпта вводим свой необходимый промпт и обязательно используем наше теговое название. (instagirl для включения lora instagirl v.2.5, l3n0v0 для ультрареализма)
Генерируем изображения и радуемся результату.
Генерируем 18+ видео с помощью WAN 2.2
В этой части инструкции мы научимся генерировать 18+ видео с помощью нейросети WAN 2.2 на арендованном сервере с GPU на Runpod.
Регистрация и пополнение баланса
Для реализации нашего плана необходимо зарегистрироваться на Runpod (реф., при пополнении баланса на 10$ и более получишь бонус 5$). После регистрации нам необходимо пополнить счет (минимальная сумма 10$) перейдя на страницу Billing (принимаются только зарубежные карты, я использую сервис WantToPay для оплаты). После пополнения баланса можно приступить к следующему этапу.
Аренда и настройка сервера
Для начала нам необходимо арендовать хранилище (в этом хранилище будут храниться наши модели и прочие данные не зависимо от того запущен сервер или нет). Переходим на Storage и нажимаем на New network volume. Тут у нас справа находятся GPU, а слева датацентры в которых они находятся. К примеру нажав на L40s (можно выбрать другой 🙂 мы можем увидеть что он доступен в 2 датацентрах:

Нажимаем на датацентр и смотрим чтобы у GPU доступность была хотябы Low. (если N/A то нет свободных GPU). Так же необходимо написать название нашего хранилища (любое) и выбрать размер (лучше 100 гб с запасом). После этого нажимаем на Create Network Volume и создаем хранилище:

Можно выбрать и другой GPU но при этом vram необходимо чтобы было не меньше 48 GB:

Нажимаем на GPU и дальше нас перекинет на выбор конфигурации:

Нажимаем на Change template и выбираем ComfyUI Manager Permanent Disk torch2.4. Ниже нажимаем кнопку Deploy on demand. После этого начнется запуск нашего сервера. Его мы можем найти во вкладке Pods. Заходим в pods и нажимаем на наш сервер, откроется боковое меню, там переходим на вкладку Logs и дожидаемся появления сообщения Start scripts finished (на это может уйти 5-10 минут):

Далее переходим во вкладку Connect и нажимаем на JupiterLab:


В JupiterLab открываем терминал:

и начинаем скачивать нужные файлы на сервер. Все файлы у нас будут находиться в директории ComfyUI/models в соответствующих папках. С помощью команды cd ComfyUI/models переходим в папку models. После перехода можем набрать команду ls -a и убедиться что есть нужные нам папки. Далее переходим в папку text_encoders с помощью команды cd text_encoders. И загружаем туда нужный файл с поомощью команды wget {ссылка на файл}. (Все ссылки на файлы находятся ниже.) После окончания загрузки с помощью команды cd .. (переход в предыдущую папку) переходим обратно в models. Продолжаем переходит по папкам и скачивать нужные файлы:

text encoders: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
vae: https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors
diffusion models: https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
loras: https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/loras/wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors
https://huggingface.co/NSFW-API/NSFW-Wan-14b-Sex/resolve/main/nsfw_wan_14b_sex.safetensors
checkpoints: https://huggingface.co/NSFW-API/NSFW_Wan_14b/resolve/main/nsfw_wan_14b_e15.safetensors
Запуск ComfyUI
Открываем новый терминал в JupiterLab и пишем туда ./run_gpu.sh (Необходимо убедиться что текущая директория это workspace). Скрипт запустит ComfyUI на GPU:

в терминале ждем появления сообщения [ComfyUI-Manager] All startup tasks have been completed. После этого обратно открываем наш Pods и уже нажимаем на ссылку ComfyUI:
Сейчас мы можем открыть наш Workflow (сначала скачать на комп) на ComfyUI. Открываем наш скаченный файл Workflow:

Откроется Workflow:

Рассмотрим самые важные детали. Кнопка Run запускает процесс генерации. Positive prompt — сюда пишем наш промпт. Negative prompt — сюда пишем чего не хотим видеть в результате. EmptyHunyuanLatentVideo — тут указываем разрешение видео и длину (длина в кадрах, тут 81 кадр, при fps 16 это получается 5 секунд 81/16=5 (Необходимо сделать длину на 1 кадр больше) если надо 10 секунд то 10*16+1 = 161).
Запускаем процесс генерации и получаем результат во вкладке Queue. (на генерацию видео уходит около 500 секунд, в случае gpu rtf 4090). Нажимаем на видео, смотрим и сохраняем как mp4 файл на комп.

Рекомендую использовать Гайд для промптов. Файл большой, можно найти рекомендации по генерации видео в разных стилях.
Математика: аренда rtf 4090 стоит 0,6$ в час. Видео генерируется около 500 секунд. Одно видео обойдется в 0,08$.
Для завершения работы необходим в меню Pods сделать Terminate для нашего сервера:

Это остановит сервер, но наши файлы останутся на storage, чтобы позже опять запустить сервер опять заходим в Pods, выбираем наш Storage и gpu и запускаем сервер как в начале инструкции.
